
こんにちは、DX攻略部のモンです。
今回はGoogle Cloud BigQueryに保管しているデータをTableauと連携して活用する方法について解説していきます。
ビジネスの現場にデータが溢れる2026年、データの「所有」と「活用」の間には依然として大きな壁が存在します。
特にGoogle CloudのBigQueryに蓄積された膨大なデータを、SQL(プログラミング言語)が書けないノンプログラマーが自在に操ることは、かつては不可能に近いことでした。
その問題に対して、TableauはSQLを使わずに大量のデータを処理し、簡単にビジュアライズできるBIツールなのです。
Tableau(タブロー)の直感的なインターフェースと、最新のAI機能を駆使すれば、エンジニアの手を借りずとも、わずか30分で生データから戦略的なインサイトを導き出すことが可能です。
また、業務データの分析を直感的に誰もができるようになるため、組織の意思決定速度の上昇やデータからの新たな課題の発見が見込めます。
この記事では、BigQueryとデータを連携して具体的にどのようなビジュアライズができるかもご紹介します。
DX攻略部では、企業のDX化に関する相談を受け付けていますので、ぜひご相談ください。

Tableauとは?
まずは、Tableauがどういったツールか確認していきましょう。
TableauはSalesforce社が提供するツールの1つ
Tableauは、Salesforce社の提供するビジュアル分析プラットフォームです。
直感的な操作でさまざまな形式のデータを瞬時にビジュアライズできるので、非エンジニアでもデータベース内のデータを簡単に意思決定や課題発見につなげることができます。
データの取り込み方法もさまざまで、csvデータを読み込むことやスプレッドシートを直接参照することも可能です。
また、マウスのドラッグ&ドロップだけで、複雑な計算やデータの視覚化が完結する点は、魅力的な特徴です。
各社のサービスにあわせてデータの取り込みができるため、比較的導入のハードルは低いといえるでしょう。
今回はGoogle CloudのフルマネージドなデータウェアハウスであるBigQueryにあるデータを参照して、Tableauで意思決定のためのデータビジュアライズをしていきます。
2026年におけるTableau
2026年現在のTableauは、単なるグラフ作成ツールではありません。
背後で動くAIエンジンにより、データの中に潜む「異常値」や「トレンドの変化」を自動で検知し、自然言語で解説してくれる「Tableau Pulse」などの機能が統合されています。
これにより、ノンプログラマーであっても、データサイエンティストに近い視点で意思決定を行うことができるようになっています。
こんにちは、DX攻略部のkanoです。 「データウェアハウスを導入したいけど、どれを使えばいいのかわからない」 「SnowflakeとBigQueryのどちらにするか迷っている」 こういった悩みをお持ちではありませんか? […]

TableauとBigQueryを接続(連携)する
Tableauを起動するとまず、どのデータソースからデータを取り込むかを求められます。
Tableauのデータ接続
TableauとBigQueryの親和性は、数あるデータソースの中でも非常に高いものになっています。
Googleのアカウントさえあれば、専門的なネットワーク設定なしに、クラウド上のデータへ安全にアクセスできるのが大きなメリットです。

デフォルトで提案されるデータベースの接続方法のみで60種類程度の接続方法があり、追加できるものを含めると80種類を超えます。
この記事ではTableauでの分析を目的としたBigQueryへの接続方法を紹介しますが、ほかにもGoogle Cloudのフルマネージドなリレーショナルデータベースインスタンスを提供するCloud SQLとの連携もサポートしています。
まず、データソースの一覧から「Google BigQuery」を選択します。
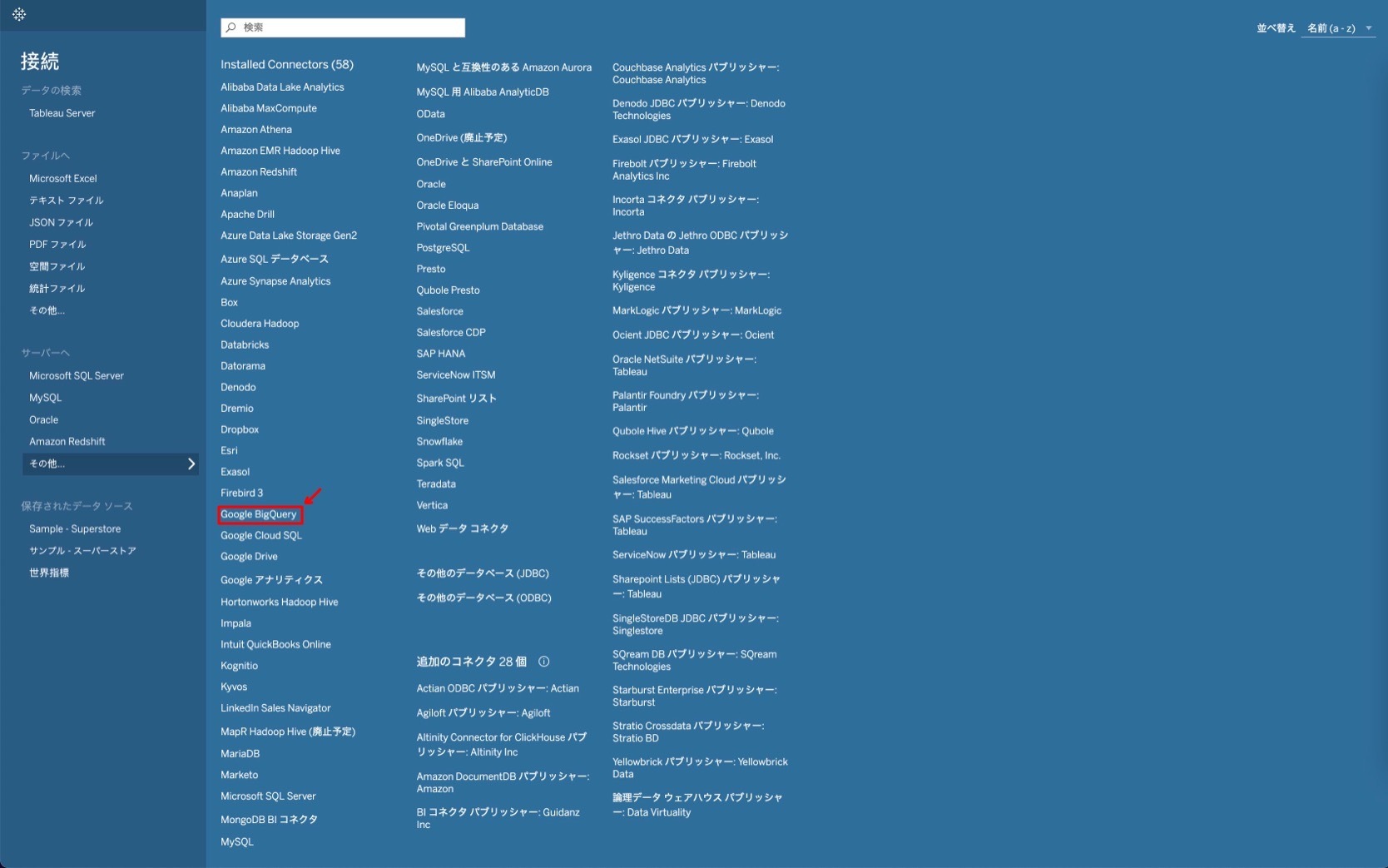
続いて、どの方法で認証するかを要求されます。認証には2種類あり、「OAuthでのサインイン」と「サービスアカウントを使用してサインイン」を選ぶことができます。
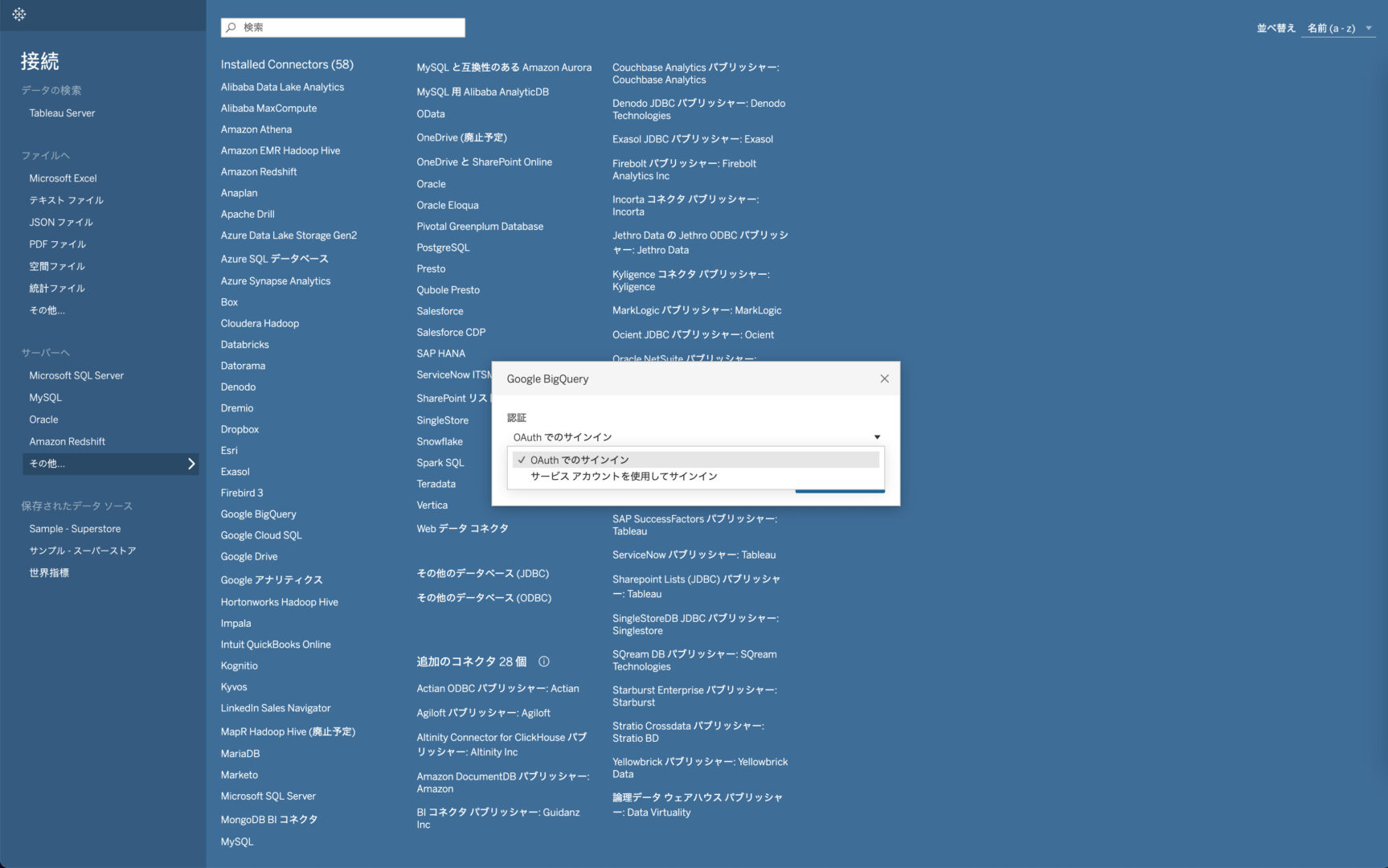
Tableauからのアクセスを、サービスアカウントとして取り扱いたい場合はjson形式のサービスアカウントキーを用意した上で後者を選択する必要がありますが、そうでなければOAuthでの認証がおすすめのため、本記事ではOAuthでの認証を紹介します。
「OAuthでのサインイン」を選択後、Googleからログインするアカウントを要求されるので、接続したいGoogle Cloudのプロジェクトへのアクセス権限のあるユーザーとしてTableauでログインをします。
ログイン成功後、Tableauからのアクセスについて許可を求められるので「許可」を選択してください。
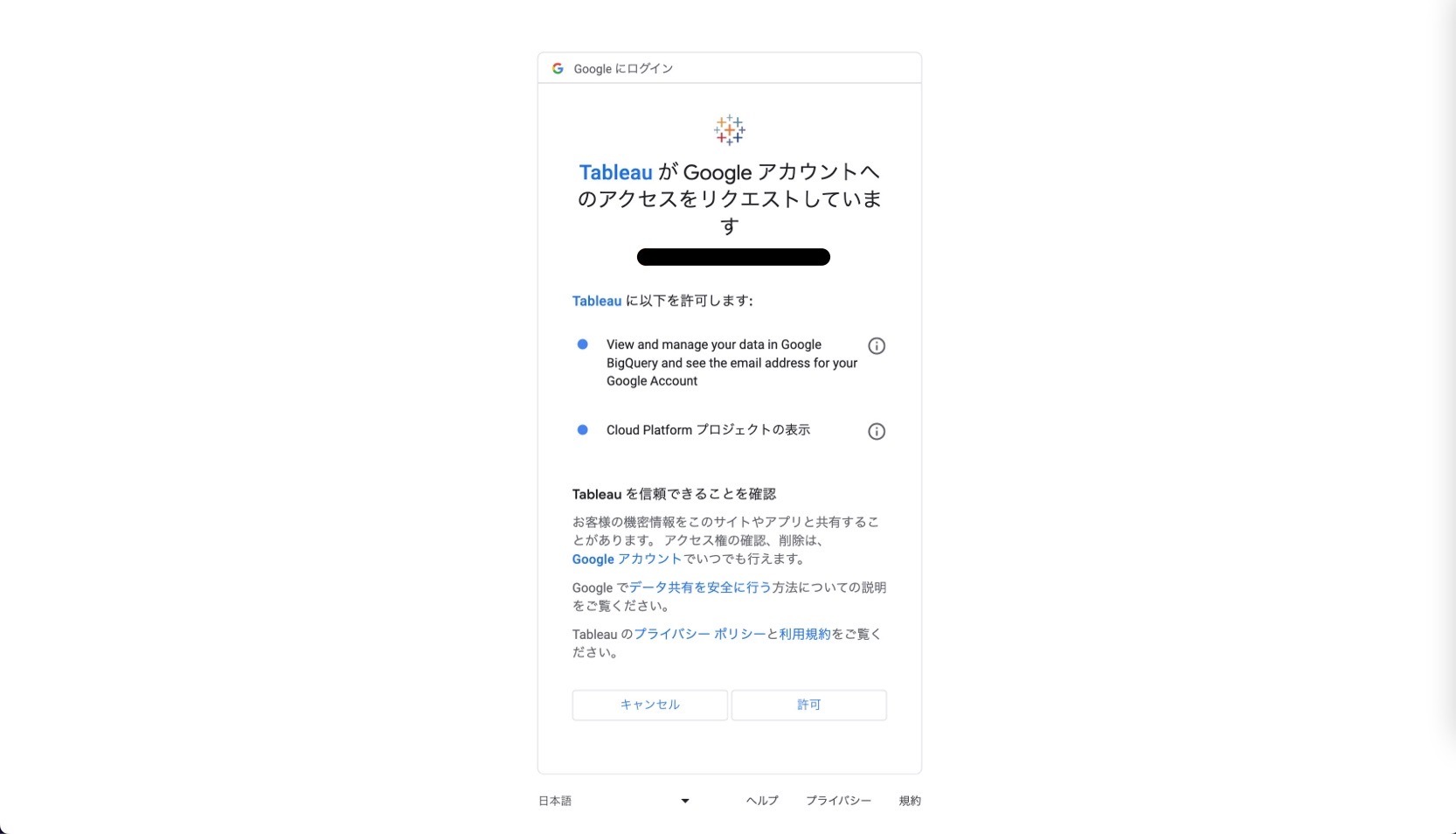
Tableau created this window to authenticate. It is now safe to close it.と表示されれば接続完了です。
「OAuthでのサインイン」の場合に必要な接続の設定はこれだけです。
問題なく接続されると、以下のスクリーンショットのような画面が表示されるはずです。
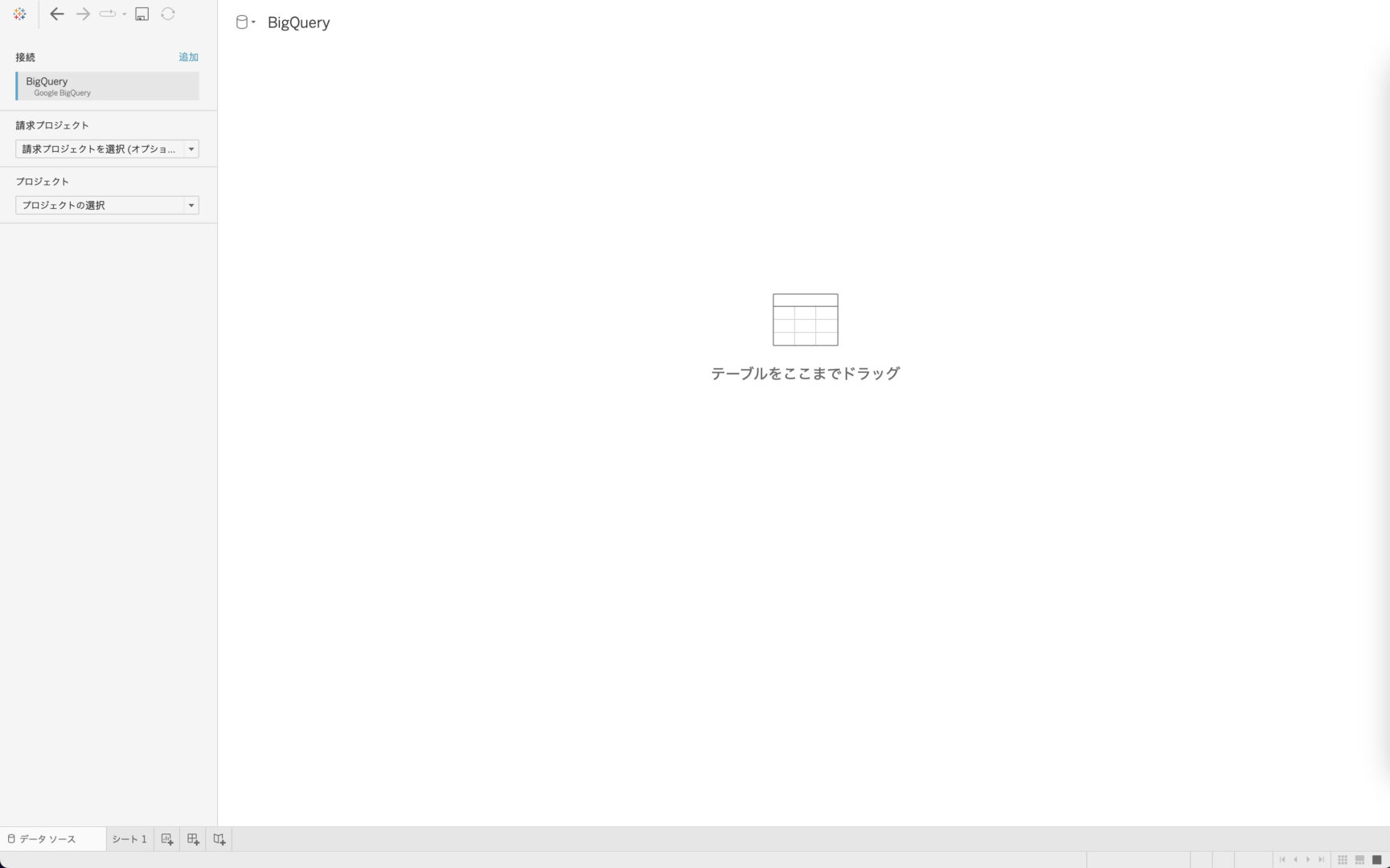
さっそく、接続されたデータの確認をしていきましょう。
Google CloudのBigQueryとCloudSQLのクエリ実行の請求体系は以下のようにことなります(詳細はサービスページをご覧ください)。
| BigqueryとCloudSQLの料金設定 | |
| BigQuery | SQLでスキャンをした行と列のデータサイズに応じて請求。 |
| CloudSQL | インスタンスの起動時間に応じて請求。SQL実行では請求なし。 |
上記の請求体系を鑑みると、CloudSQLに接続して分析する方がよいように思えてしまいます。
しかし、CloudSQLの主な用途は「分析対象のサービスで提供しているデータなどをストアすること・そのデータに問い合わせをすること」であるため、サービスの本番環境のデータベースサーバーに高負荷な分析用SQLで問い合わせしてしまうとサービスのパフォーマンスが下がってしまう可能性があります。
そのため、迂闊なCloudSQLへの接続は避けるほうが無難です。
こんにちは、DX攻略部のkanoです。 多くの企業でGA4の導入が進みましたが、そのデータを単なるサイト計測で終わらせてはいませんか。 真のデータ活用とは、GA4の行動データとCRMの成約データを統合し、ビジネスの意思決定を支える生きた[…]

BigQueryのデータの確認とTableauの接続設定
BigQueryとTableauの接続設定を確認していきましょう。
BigQueryの接続確認
画面の左側に「請求プロジェクト」「プロジェクト」が表示されている状態で、取り扱うデータのある「請求プロジェクト」「プロジェクト」「データセット」を順に選択していくと、データセット内のテーブルが一覧で以下の画面のように表示されます。

取り込みたいテーブルをダブルクリックで選択すればそのテーブルの情報がすべて読み込まれます。
データが読み込まれると、以下のスクリーンショットのようにフィールドの情報(名称やデータの型など)とデータのプレビューが表示されます。
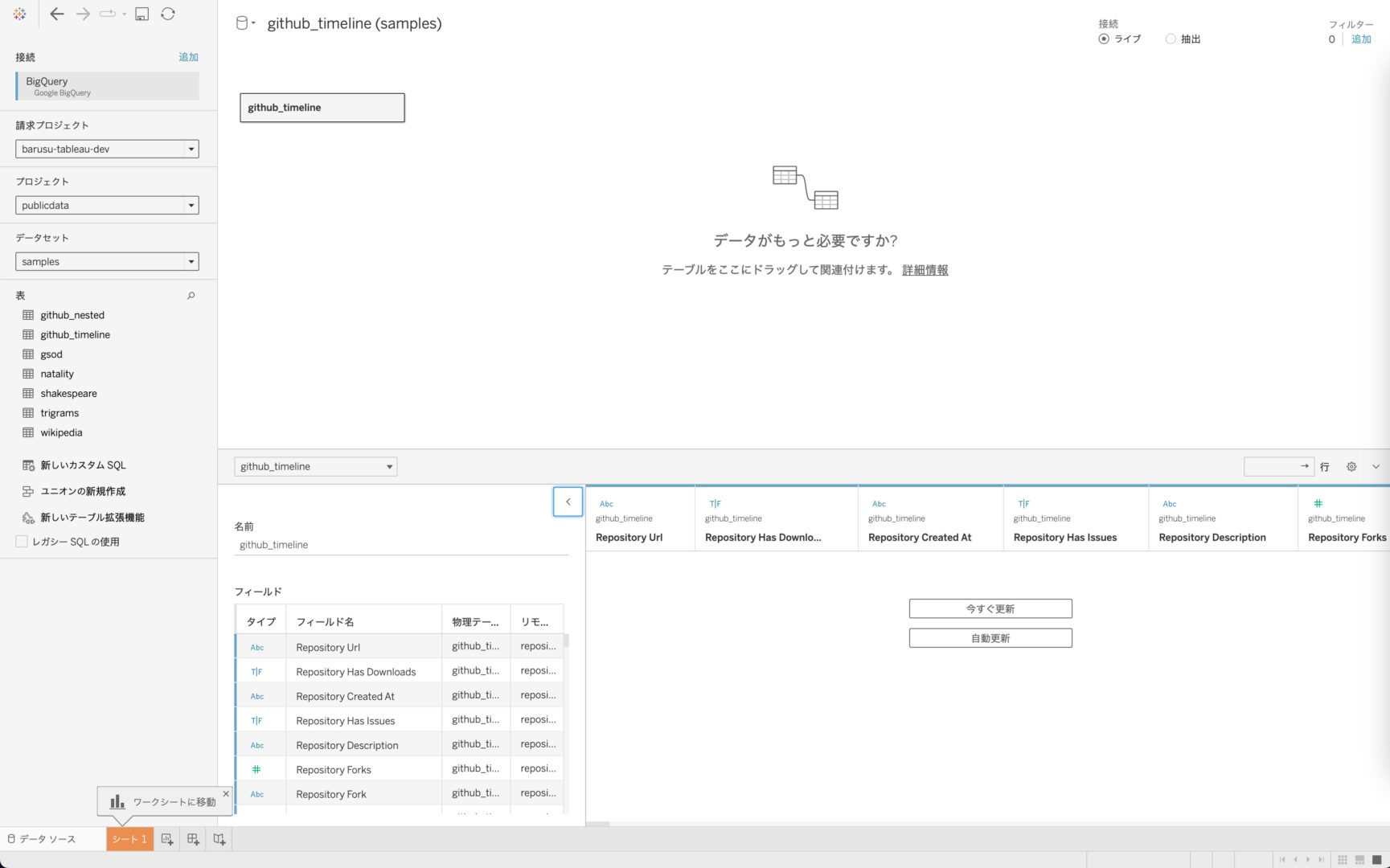
たったこれだけの動作でデータベースからのデータの取り込みが完了しました。
データを整形する前に、コストが気になる場合は画面右上部にある「接続」設定を「ライブ」から「抽出」に変更しておきます。
「ライブ」接続のままだと、データが意図しないタイミング・頻度で更新される可能性があり、コストが余計にかかってしまう場合があるので注意です。

BigQueryへの接続においてどのようにコスト削減をすればよいのでしょうか。
以下の2種類の対応を用途によって使い分ける、あるいは組み合わせることをおすすめします。
①Tableauでデータを「ライブ接続」ではなく「抽出」に設定する。
「ライブ接続」設定ではVizが表示されるたびにデータを取得し直します。
ここからもわかるとおり、膨大なデータをスキャンするクエリの場合、アクセスのたびに毎回スキャンをするとコストが膨大になってしまいます。「抽出」設定では一度スキャンしたデータを保存してVizを作成することができます。
さらに、抽出の頻度を細やかに設定できるため、1日に1度の更新などの設定をおすすめします。
ただし、コストがかかりにくい分、データを全て保存するため膨大なデータ量になる場合はパフォーマンスがそのぶん下がる点に注意です。
なお、2026年の推奨運用では、アドホック(その場限り)な分析を除き、原則として「抽出」を選択します。
抽出を行うことで、一度データを取り込めば、その後の操作はBigQueryにクエリを投げないため、課金を抑えつつ、サクサクと快適なスピードで分析を進めることができます。
②BigQueryで事前にダッシュボード読み込み用データ(いわゆるデータマート)を作成しておく。
上述の読み込みデータ量が多いとパフォーマンスが下がる点について対応しつつ、コストを削減できる方法がこの方法です。
Tableauに実行させたいデータの読み込み、集計の過程を事前にBigQuery内で実行し、その結果をテーブルとしてBigQuery内に保存しておきます。
すでに集計されている結果のみをTableauが読み込むことになるため、Tableau側は非常に軽量なデータを取り扱うのみで済みます。
また、Tableauからの読み込みにかかるコストも、データが軽量であるため低額で済むため、「ライブ接続」設定でかなりの回数のスキャンがされても総額として比較的安く済むことが多いです。
ただし、BigQueryで事前にテーブルを作成する際に集計コスト自体はかかり、そのうえで低額とはいえTableauからの読み込みにコストがかかるため①の手法にかかるコストよりも安くなることはありません。
これらの方法をうまく組み合わせて、そのダッシュボードの用途にあわせて、どちらかを適用・あるいは両方を適用してみてください。
こんにちは、DX攻略部のkanoです。 Googleが提供する超高速データウェアハウスであるBigQueryは、今やデジタルマーケティングの成否を分ける心臓部と言っても過言ではありません。 GA4の生データを蓄積し、CRMや広告データと[…]

Tableauでビジュアライズしてみる
Tableauの真骨頂といえる、ビジュアライズを設定していきましょう。
ビジュアライズの設定
Vizの作成を始めるためにはデータを読み込んだ後に「シート」に移動します。
シートに移動すると以下のスクリーンショットのように、左側に読み込まれたデータのフィールドが一覧になっています。
フィールドは日付や文字列・カテゴリカルなデータなどの定性的値が「ディメンション」として、測定可能な数値や定量的値が「メジャー」として自動で分類されています。もちろん自動でされた分類を逐次変更することも可能です。
Tableauでは、可視化したいフィールドを右側のワークスペースに配置するだけでさまざまなビジュアライズを作成できます。
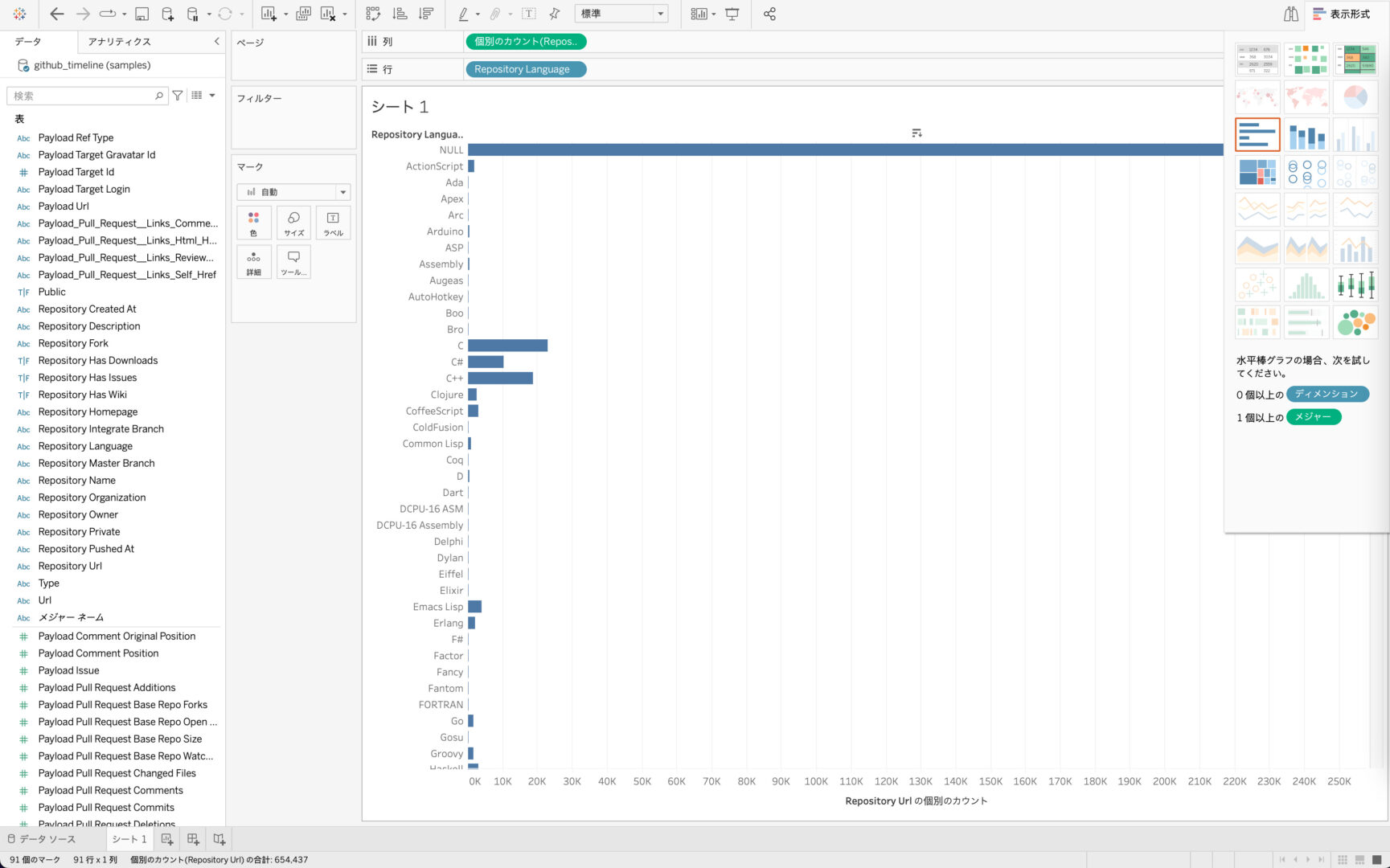
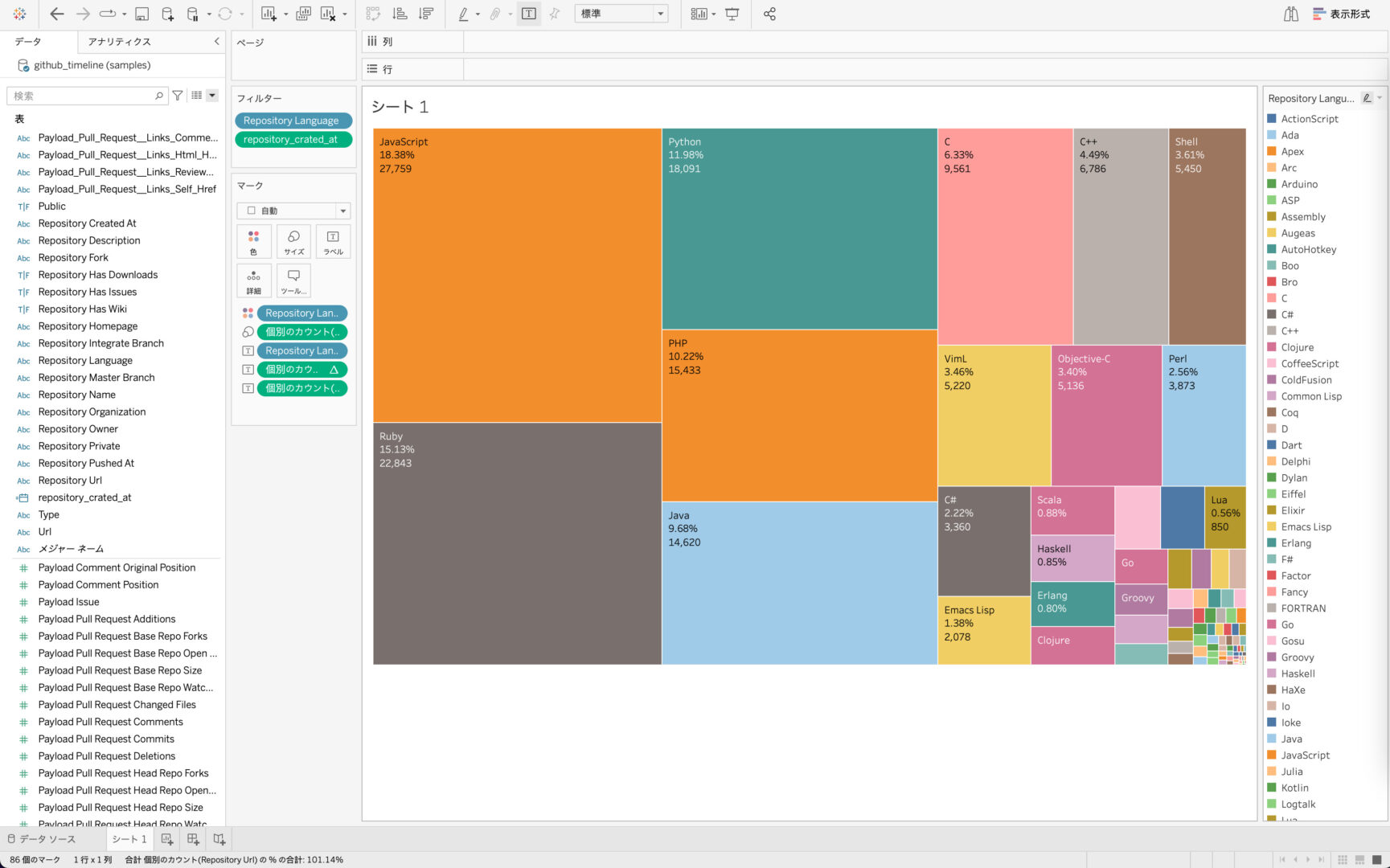
取り込んだデータが2012年までのGitHubのリポジトリに関する情報なので、今回は「2008年から2011年にGitHubで作成されたリポジトリでどの言語のものが多かったのか」を可視化したいと思います。
「repository_language」ごとに「repository_url」がいくつあるのかを集計し、「repository_created_at」で期間を指定することでわかりやすいアウトプットを作成できそうです。
では、「repository_language」と「repository_url」のフィールドをワークスペースに移動してみましょう。
「repository_url」はディメンションとして読み込まれていますが、「いくつあるのか」を集計したいので、スクリーンショットのように「メジャー」>「カウント(個別)」とすることで「repository_url」のユニークな個数を集計したメジャーに変換することができます。

「repository_language」ごとの「repository_url」の個数が棒グラフで表示されました。
ビジュアライズに慣れていればフィールドを適切に配置できると思いますが、扱い慣れていない方には画面右上の「表示形式」の活用をオススメします。
代表的なビジュアライズはほとんどが「表示形式」のテンプレートにあるので、必要な情報をワークスペースに追加してからテンプレートを適用してみます。
ツリーマップのテンプレートを適用すると以下のスクリーンショットのようなVizが自動でできあがります。
最後にカラーリングの設定やラベルの設定を変更して、以下のようなVizができあがりました。ビジュアライズすることで、規模の大小関係も即座に理解できるようになりましたね!
データの接続からビジュアライズまで、慣れれば10分もかからずにできることがTableauの大きな強みといえます。
こんにちは、DX攻略部のkanoです。 Salesforce、Shopify、Stripe、GA4(Googleアナリティクス4)、便利なツールを導入すればするほど、なぜか現場の集計作業は増えていくという、そんな矛盾を感じてはいませんか。[…]

カスタムSQLで集計データを読み込む
基本操作に慣れてきたら、特定の分析に特化した「カスタムSQL」の活用も視野に入れます。
カスタムSQLの設定
データの取り込み段階で必要なデータがわかっているのであれば、SQLによるデータの問い合わせをTableauに実行させて無駄なデータを読み込まないようにする方法もあります。
BigQueryのようにスキャンしたデータ量に応じて課金される場合はコスト削減にも繋がりますし、取り込むデータの量が減ればTableauで作成する抽出データも軽くなるためTableauのパフォーマン向上にもつながります。
カスタムSQLを用いて、さきほどと同じVizを作成していきましょう。
データソース接続後、テーブル一覧の表示される画面で「新しいカスタムSQL」を選択します。
以下のスクリーンショットのようにSQLを入力できるフォームが表示されるので、BigQueryに対応したSQLを直書きしましょう。
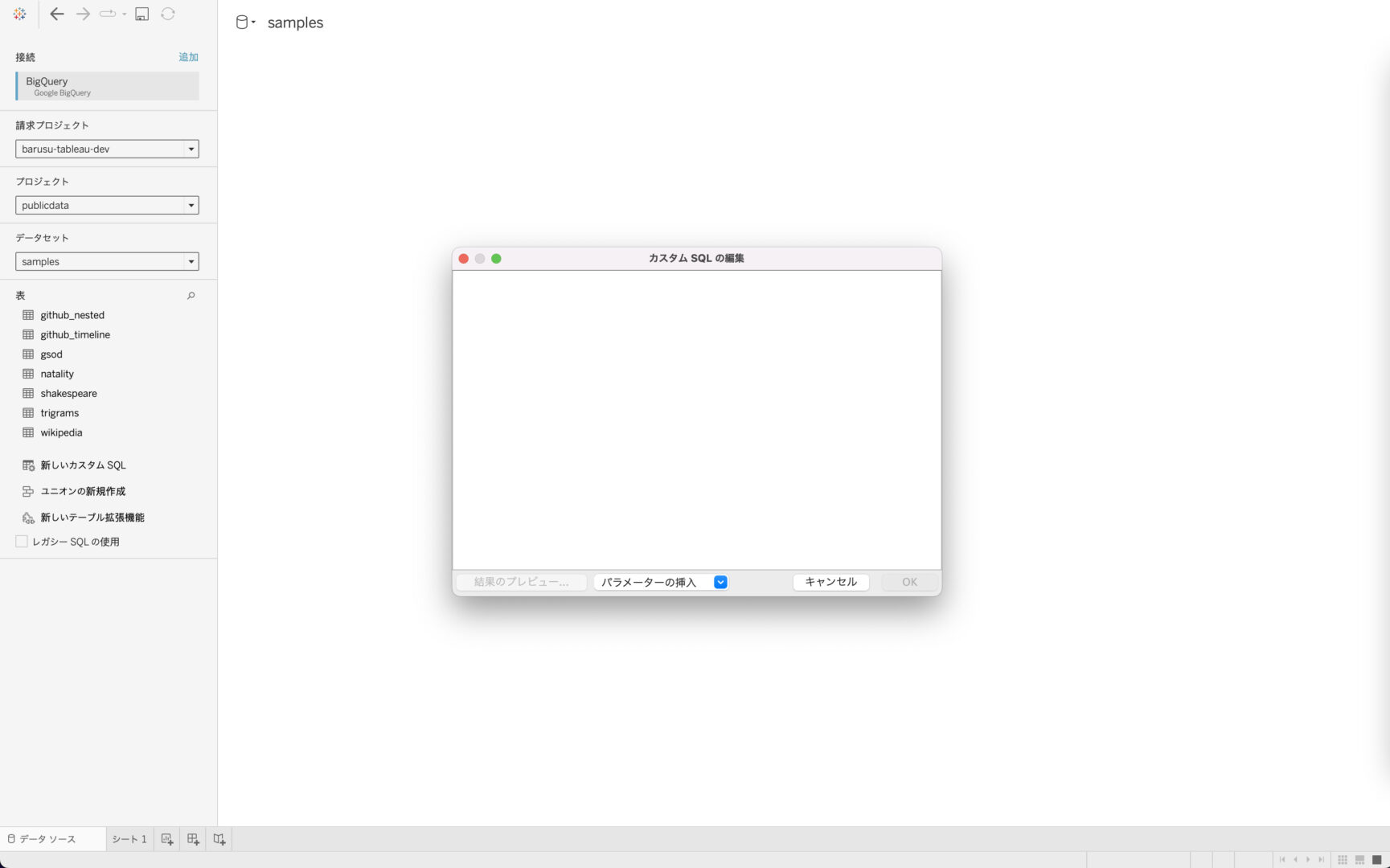
今回は以下のSQLをいれました。
select
repository_language,
count(distinct repository_url) repository_count
from
bigquery-public-data.samples.github_timeline
where
repository_created_at between '2008-01-01' and '2011-12-31'
and repository_language is not null
group by
repository_language
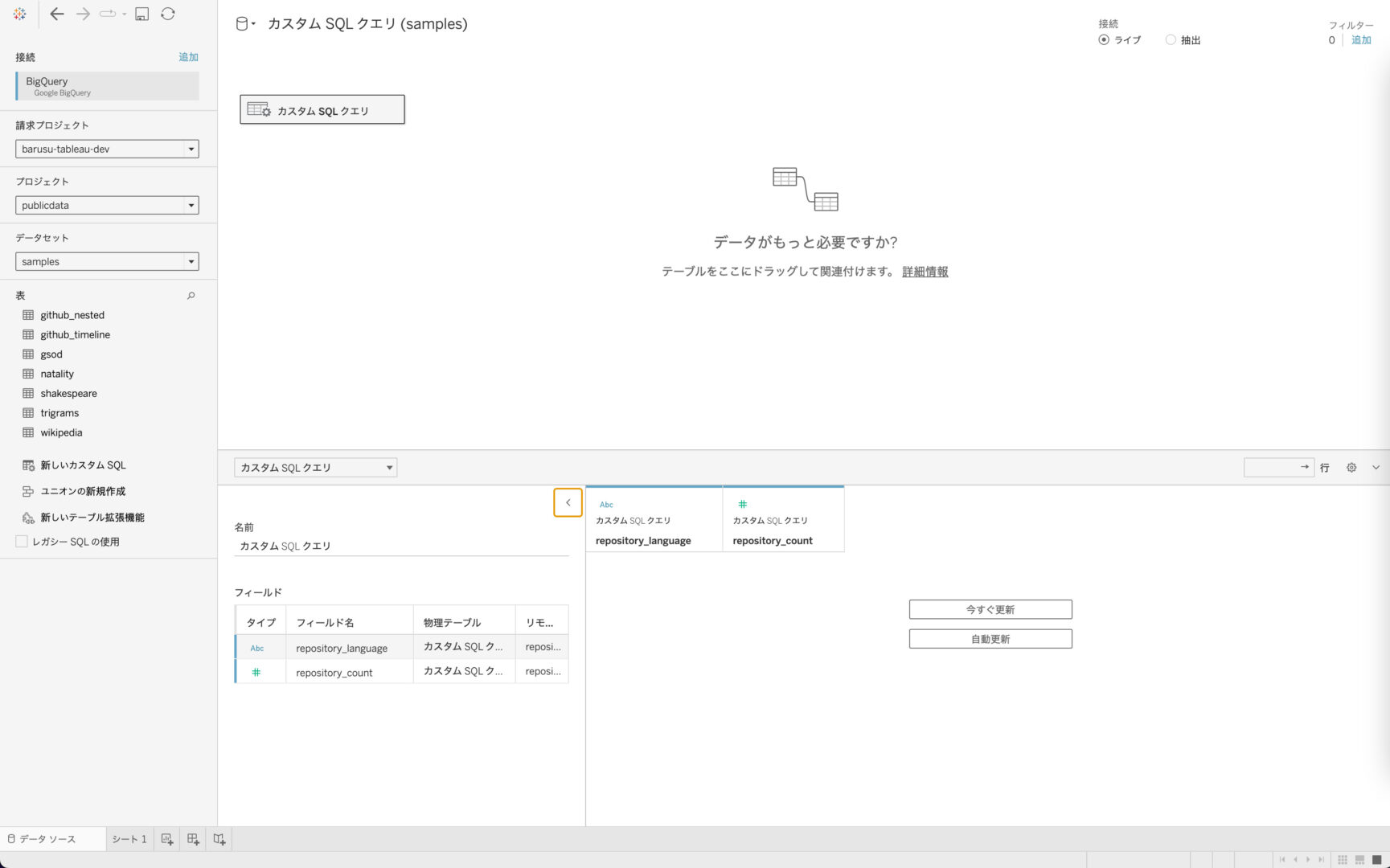
SQL入力後、「OK」を押すとBigQueryで入力したSQLを実行してデータを取得してくれます。
集計をして情報量を落としているので、データのフィールドもかなりコンパクトになりました。
さきほどと同様にVizを作成していきます。
SQLの段階でデータの取捨も行なっているため、「repository_language」と「repository_count」を選択して,表示形式でツリーマップを押下するのみで先ほどと同様のVizが仕上がりました。
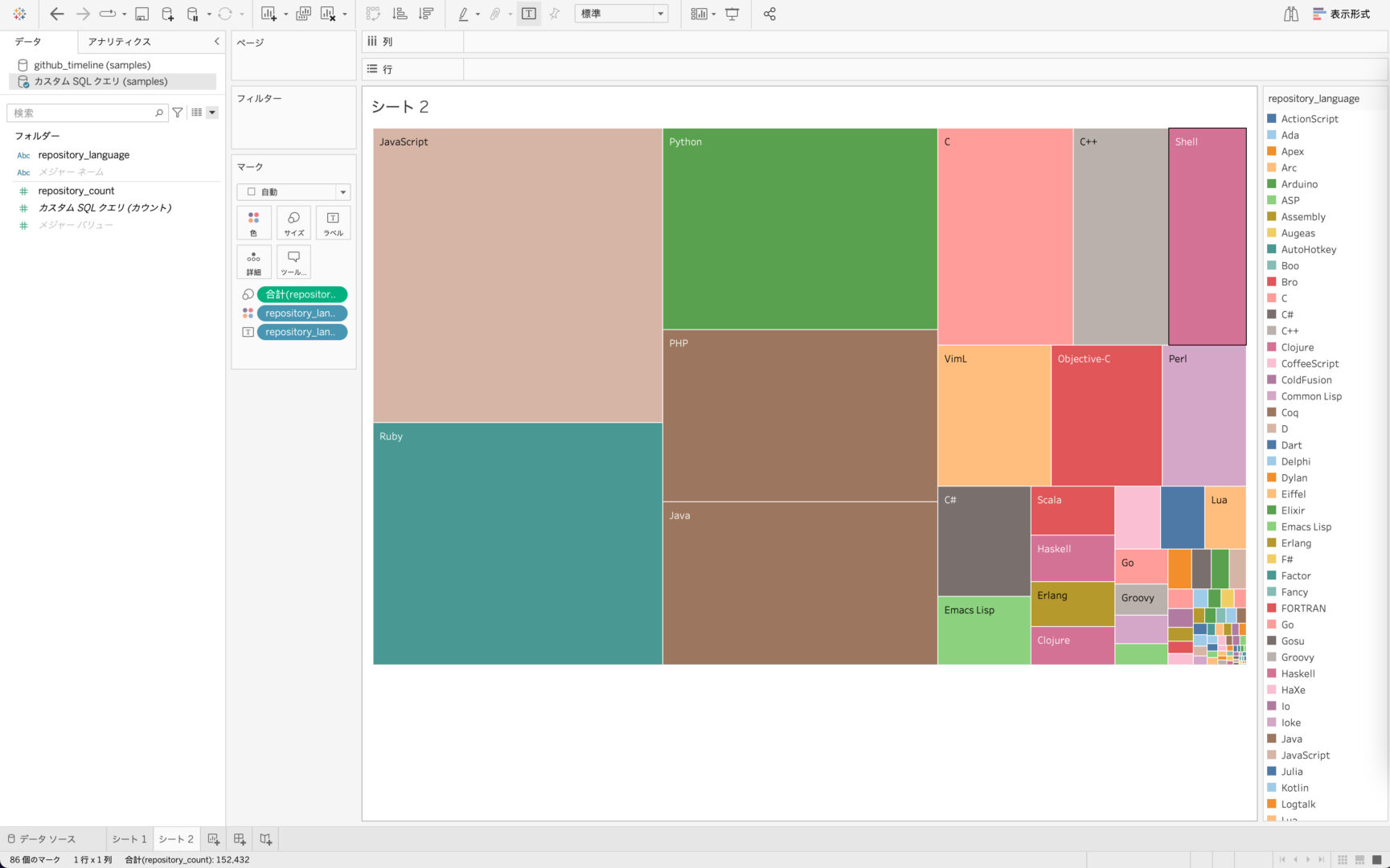
今回は作りたいVizが事前に決まっていてカスタムSQLで必要なデータしか用意しなかったため、逆にこれ以外のVizを作成できないデータになってしまっています。
動作の軽量さと分析の柔軟さはトレードオフの関係になっているともいえるので、探索的な分析は柔軟さを優先し、ダッシュボーディングなどではパフォーマンスを優先するなどして目的に応じて使い分けることをオススメします。
また、Tableauの利点としては上記のようなSQLを書かずとも、同様のデータ処理ができる点にもあると思います。
SQL習得のための時間のないビジネスマンにとっても、データドリブンな意思決定をサポートしてくれる強力なツールであるといえるでしょう。
こんにちは、DX攻略部のkanoです。 「Salesforce、MAツール、基幹システムなど導入ツールは増えたが、かえって顧客の全体像が見えにくくなった」と感じていませんか? SaaSの乱立によって生じる「データのサイロ化」は、[…]

まとめ
ここまで、Google Cloud BigQueryとTableauの連携について解説してきました。
SQLを書かなくても、簡単にデータの探索的な分析・ビジュアライズやダッシュボーディングができることがおわかりいただけたと思います。
AIが一般的に普及した現代において、Tableauもその要素を取り組んで進化し続けている点も注目していきたいですね。
現在、サービスのデータ基盤をGoogleCloud上に用意しているが分析にあたって技術者を仲介しなければならないビジネスマンのみなさんにとって業務の効率化やデータ活用のヒントにつながれば幸いです。
また、DX攻略部ではTableauに関するコラムやSalesforceで連携できる他のツールについて紹介しており、企業のDX化に関するご相談を受け付けておりますので、ぜひご相談ください。
