
こんにちは、DX攻略部のkanoです。
「Snowflakeをもっと便利に活用したい」と思ったことはありませんか?
Snowflakeを使い始めると、「データを取り込む作業」そのものが意外とボトルネックになります。
特にログやSaaSエクスポートのように小さなファイルが頻繁に届くケースでは、手動運用や定期バッチだと遅延や運用負荷が積み上がりがちです。
そこで役立つのがSnowpipeです。
Snowpipeはクラウドストレージに届いた新着ファイルをきっかけに、Snowflakeへ継続的に取り込みを進める仕組みで、数分単位での反映を狙えます。
本記事では、Snowpipeで何が自動化できるのかを押さえたうえで、登場要素(ステージ、パイプ、テーブル)と全体の流れ、方式の選び方(自動インジェスト/REST)、コストと権限設計までを順番に整理します。
読み終えるころには「自社はどの方式で、どこに注意して始めるべきか」が判断できる状態を目指しましょう。
そして、DX攻略部では、Snowflake×Streamlitを活用した統合BI基盤構築支援サービスを行っています。
記事の内容を確認して、Snowflakeを自社に活用してみたいと考えた方は、下記のボタンをクリックしてぜひDX攻略部にご相談ください!
Snowpipeとは
この章では、Snowpipeを「一言で言うと何か」と「どんな場面で効くのか」を先に整理します。
最初に用途を押さえておくと、後半の仕組みや方式選びがスムーズになります。
Snowpipeを一言で言うと?
Snowpipeは、クラウドストレージ(S3、GCS、Azureなどのファイル置き場)に新しいファイルが置かれたことをきっかけに、Snowflakeへ自動で取り込みを進める仕組みです。
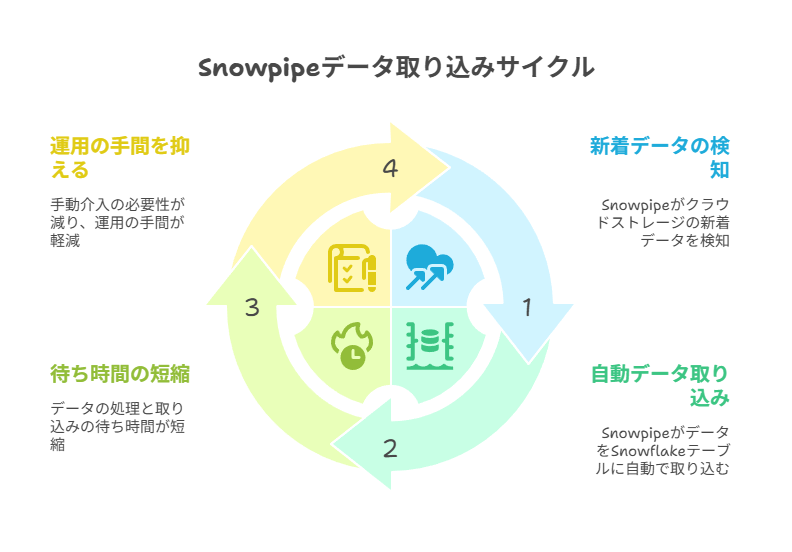
「継続的データ取り込み」とは、決まった時刻にまとめて取り込むのではなく、届き次第に近い形で取り込みを回し続けるイメージです。
定期バッチ(あらかじめ決めた時間に実行する取り込み)と比べて、データが使えるまでの待ち時間(レイテンシ)を短くしやすく、運用担当者の手作業も減らせます。
Snowpipeはどんな課題を解決するか
Snowpipeが効くのは、「小さなファイルが頻繁に届く」タイプの取り込みです。
たとえば、アプリのログ、広告やMAのエクスポート、外部SaaSからの定期出力などは、ファイル到着のタイミングが揺れたり本数が増えたりしやすく、手動運用だと漏れや遅延が起きがちです。
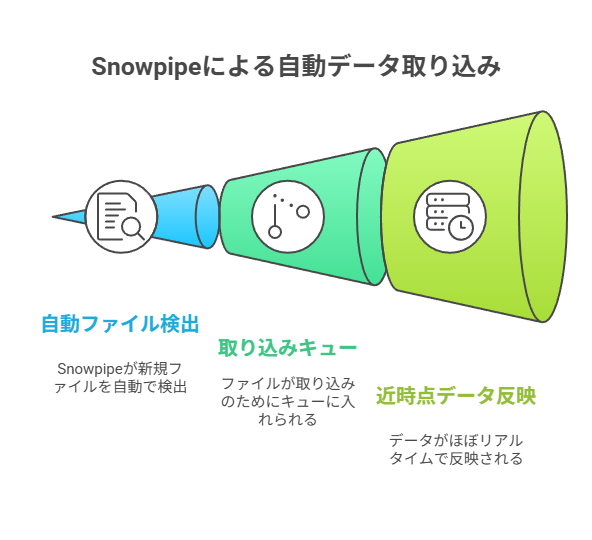
Snowpipeは新着ファイルを検知すると取り込み待ち(キュー)に登録し、数分単位の小さな取り込み(マイクロバッチ)で自動反映を進めます。
その結果、担当者が「いつCOPYを回すか」を気にする時間が減り、分析や可視化の鮮度も上げやすくなります。
目安としては「日次で十分」よりも、「数分〜数十分で反映したい」業務に向くと覚えておくと判断が速くなります。
こんにちは、DX攻略部のkanoです。 「SnowflakeのSnowparkで何ができるの?」 こういった疑問をお持ちではありませんか? Snowparkは、Snowflakeの中でPythonなどのコードを動かし、デー[…]

仕組みの基本
ここではSnowpipeがどのように新着ファイルを見つけて、どのサーバーも用意せずに数分でテーブルへ流し込むのかを、全体の流れがつかめる順番で確認します。
細かな設定よりも、まずは登場要素と動く順番をイメージできることをゴールにしましょう!
Snowpipeを使うと何が自動になるのか
自動になるのは「見つける→取り込みを回す→結果を残す」までです。
具体的には、新着ファイルの検知、取り込み待ちへの登録、COPY処理の実行、成功/失敗の履歴記録が自動化されます。
一方で、ファイルをどこに出すか(パス設計)や、どの形式で出すか(CSV、JSON、Parquetなど)、エラー時の扱い(止めるか、飛ばすか)は設計が必要です。
つまり、Snowpipeは運用をゼロにするというより、運用を「例外対応中心」に寄せられる仕組みだと捉えると実務に合います。
基本の登場要素
Snowpipeの全体像は三つの要素で成り立ちます。
ファイルを置くステージ、取り込み手順を定義したパイプ、書き込み先のターゲットテーブルです。
- ステージ:ファイルの置き場所です。外部ステージ(S3/GCS/Azureなど)や、Snowflake内部のステージを使います。
- パイプ:どのステージから、どのテーブルへ、どんなCOPY設定で取り込むかを持つ設定本体です。
- ターゲットテーブル:取り込み先です。列として整形して持つか、VARIANT(半構造化データを柔軟に格納できる型)中心で持つかもここで決まります。
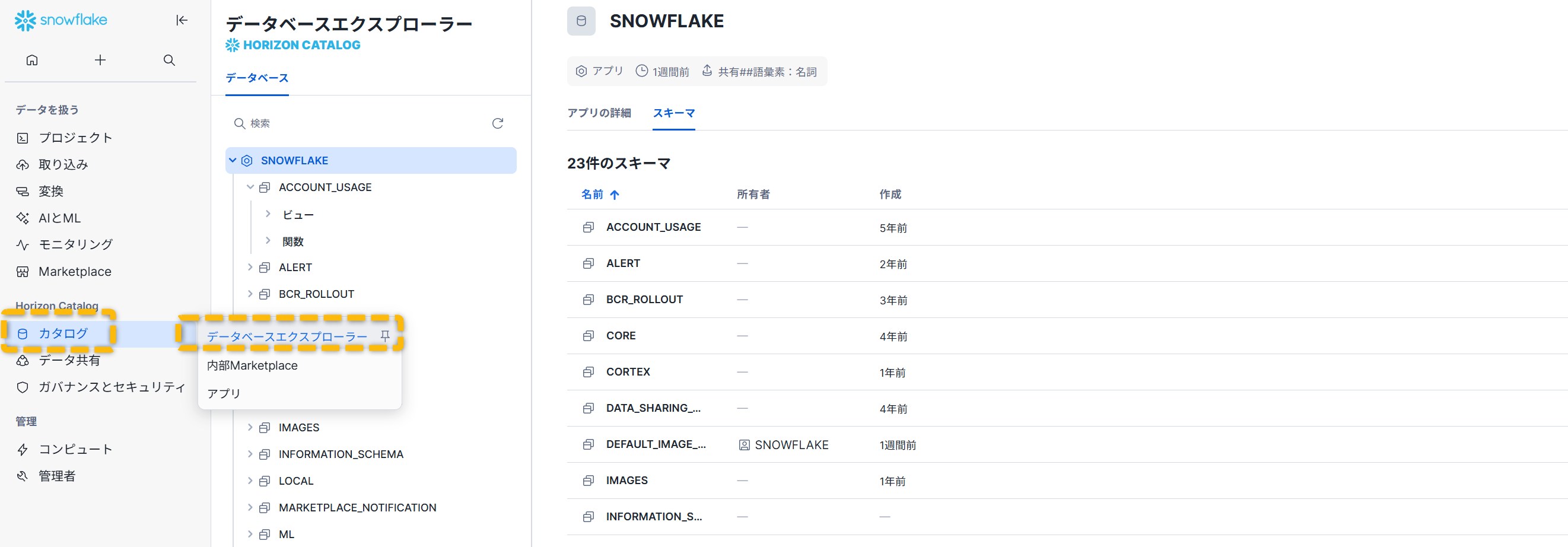
Snowsightではこれらの状態や履歴を一覧できます。
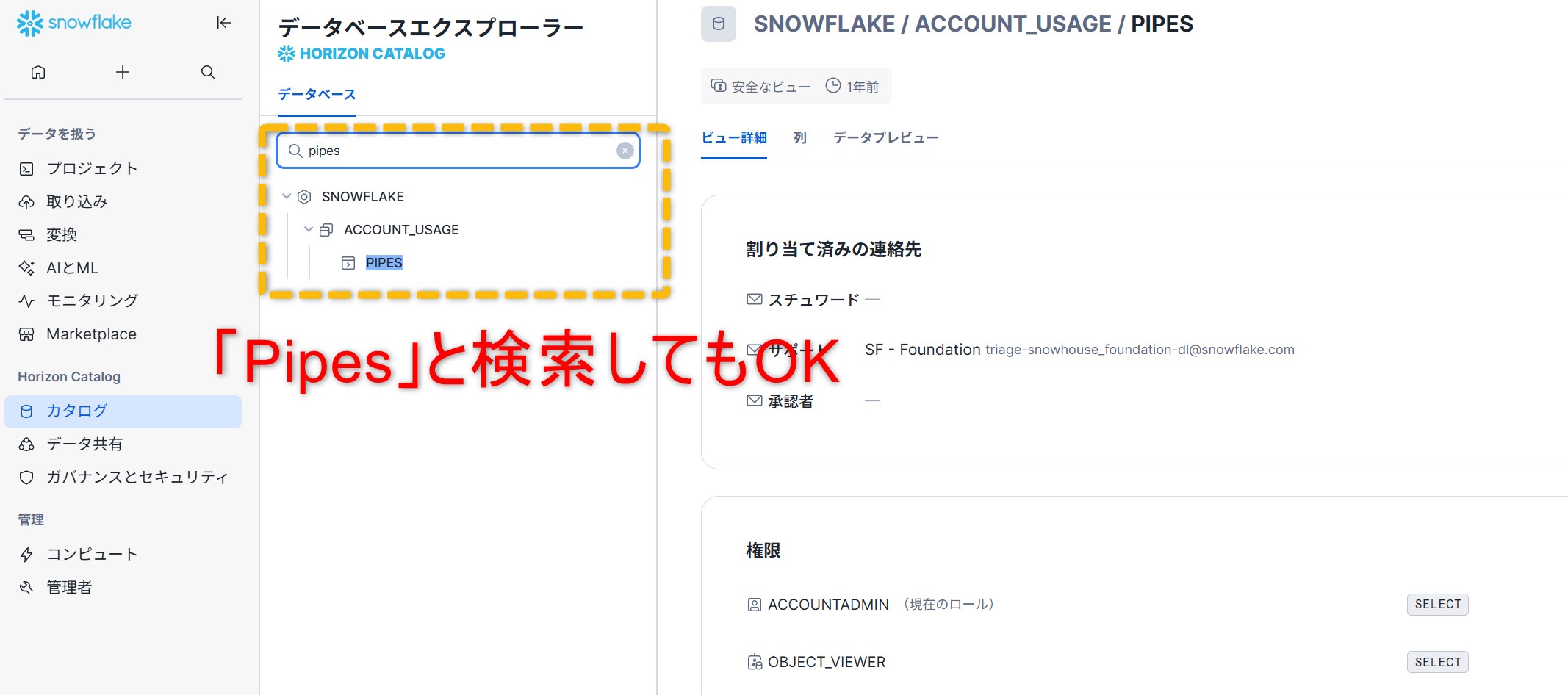
左メニューで「カタログ」→「データベースエクスプローラー」→ 対象のデータベース → スキーマ →「Pipes」→ 対象パイプを開く形で確認できます。
ステージはファイルの置き場所で、S3やGCS、Azureのバケットを外部ステージとして紐づけるか、Snowflake内部のステージを使います。
パイプはCREATE PIPEで作成するオブジェクトで、COPY INTO <テーブル> FROM <ステージ> の定義やファイルフォーマット、エラー時の扱いなどを保持します。
ターゲットテーブルはロード先で、列型テーブルに直接書き込むほか、半構造化データはVARIANT列を中心に設計することもできます。
ファイル検知の方式
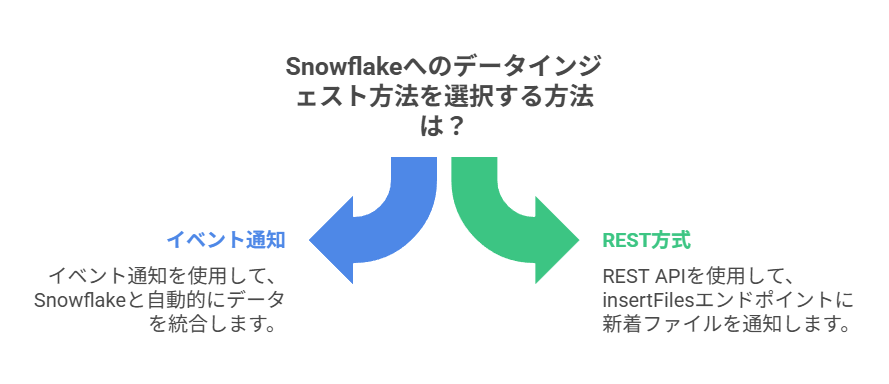
ファイルの検知方式は、クラウドイベントを使う自動インジェストと、クライアントから通知するREST方式があります。
自動インジェストは、ストレージ側のイベント通知(新着ファイルの発生を知らせる仕組み)を使ってSnowflakeへ連携する方式です。
通知の仕組みが作れるなら、まず第一候補になります。
REST方式は、アプリやジョブが「このファイルを取り込んで」とAPIで通知する方式です。
通知のタイミングを業務ロジックで握りたい、イベント設定が組織的に難しい、といった条件で選びやすくなります。
どちらを選んでも、取り込み処理自体はSnowflake側のサーバーレス計算で実行される点は共通です。
取り込みの流れを確認しよう
Snowpipeでは、ステージにファイル到着 → パイプのキューへ登録 → マイクロバッチでCOPY実行 → 成功可否とファイル名を記録 → テーブルで参照可能です。
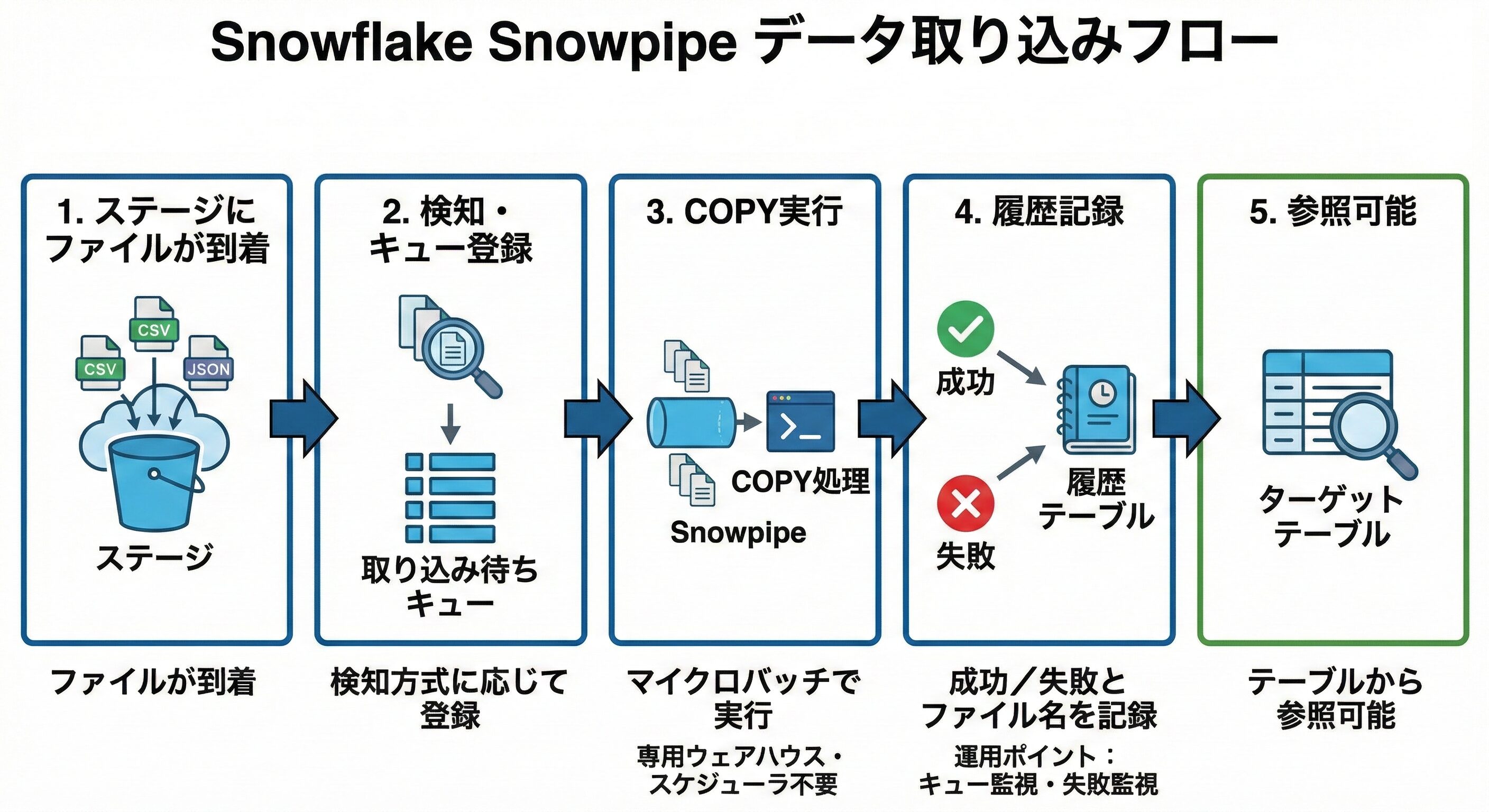
ここまでが数分の単位で回り、取り込みはSnowflakeのサーバーレス計算で実行され、ユーザー側でウェアハウスを用意する必要はありません。
重複防止と再取り込み
Snowpipeは「同じファイルを二重に入れない」ために、取り込んだファイル名やパスを記録します。
ただし、ファイル名が変わると別ファイルとして扱われるため、上流のリトライで名前が変わる運用は要注意です。
失敗時は再試行が走りますが、再試行が増えるとコスト面にも影響しやすくなります。
再実行が必要になったときのために、検証用プレフィックスと本番プレフィックスを分け、補填手順(どの期間を、どう入れ直すか)を先に決めておくと事故が減ります。
処理順序の考え方
基本は古いファイルから進みますが、内部的には並列処理があるため完全な順序保証はありません。
順序が重要なデータはファイル分割や時刻列での整合性確認を設計に入れましょう。
こんにちは、DX攻略部のkanoです。 企業のDX推進では「データを集められるか」だけでなく、「意思決定に使える状態にできるか」が成果を左右します。 ところが現場では、部門ごとにデータが分断され、集計に時間がかかり、結局は経験と勘に戻っ[…]

取り込み方式の選び方
この章では、自動インジェストとREST方式のどちらを選ぶべきかを、要件と組織制約の両面で整理します。
結論を急ぐ場合は「レイテンシ重視か」「通知設定をストレージ側で持てるか」の2点から当てはめると迷いません。
自動インジェストが向くケース
自動インジェストの強みは「新着だけを正確に知らせられる」点です。
通知対象のプレフィックスを絞れるなら、無駄な通知や無駄な再試行を減らしやすく、結果的に安定運用とコスト抑制の両方に効きます。
一方で、イベント通知の設定や権限がクラウド側に必要になるため、インフラチームと役割分担を先に決めておくと導入が止まりにくくなります。
REST方式が向くケース
REST方式は、通知の責任をアプリ側で握れるのがメリットです。
たとえば「検証に通ったファイルだけ通知する」「業務締め処理が終わったタイミングで通知する」といった制御がしやすくなります。
その代わり、重複通知のガードやリトライ設計など、アプリ側で担う運用が増えます。
イベント設定が難しい組織では現実解になりやすいので、まずは小さく始める方式として位置付けるのがよいでしょう。
判断のコツ
自動インジェストとREST方式のどちらにするかの判断のコツは、以下のようなものを参考にしてください
- レイテンシを最優先にしたいなら自動インジェストが第一候補
- 取り込みの開始タイミングを業務ロジックで決めたいならRESTが有利
- ストレージ側のイベント設定が組織的に難しい場合はRESTから始める
- 例外的な手動リカバリーや遅延ファイルの補填は、方式を問わず個別パイプまたは一時的なREST通知でカバーすると安全
同じファイル群での併用は重複取り込みの原因になるため避けましょう。
一方で用途が分かれた別プレフィックスや別パイプでの使い分けは併用が有効です。
通常運転は自動インジェスト、障害時の補填や検証はRESTといった役割分担にすると運用が整理されます。
対応データと前処理
Snowpipeがどういったデータに対応しているかについて確認していきましょう。
SnowflakeのSnowpipeの対応データの種類
SnowpipeはCSVやJSON、Avro、Parquetなど一般的な形式をサポートし、半構造化データもそのまま取り込めるため便利です。
圧縮ファイルにも対応しており、COPYオプションでファイルフォーマットやエラー時の挙動を調整します。
ファイル形式と圧縮の扱い(CSV、JSON、Parquetなど)
CSVやJSONは手軽、ParquetやAvroはスキーマ保持と圧縮率に強みがあります。
半構造化はVARIANTに入れて、必要な列だけビューやパイプラインで展開するのがポイントです。
また、極端に小さすぎるファイルはオーバーヘッドになります。
適正サイズで区切り、GZIPやSnappyなど一般的な圧縮を利用しましょう。
こんにちは、DX攻略部のkanoです。 顧客データを活用したマーケティングは「つなぐ力」で成果が大きく変わります。 Snowflakeはデータのサイロを解消し、分析と配信の両方に耐える柔軟な基盤を提供するツールです。 顧客デー[…]

導入手順の全体像
Snowpipeの実装はステージ準備、パイプ作成、通知設定、動作確認の流れで進めます。
SnowsightとSQLのどちらでも管理できますが、通知設定は各クラウドのイベント機能を使うと便利なので、そういった点も踏まえながら導入手順を確認しましょう。
ステージ準備(S3、GCS、Azure)
S3やGCS、Azureのバケットやコンテナを準備し、Snowflakeの外部ステージを作成します。
自動インジェストを使う場合はクラウド側でイベント通知を設定し、不要な通知を出さないようにプレフィックスなどでフィルタリングします。
パイプを作成する
ターゲットテーブルとファイルフォーマット、エラー時の扱いを含むCOPY定義を作り、パイプに紐づけます。
定義を変えたくなったらパイプを置換して反映します。
通知設定(イベントまたはREST)
自動インジェストならイベント通知をSnowflakeと結び付けます。
REST方式ならinsertFilesエンドポイントへ新着ファイルを通知します。
どちらも取り込みはサーバーレス計算で実施されます。
動作確認と履歴の見方
Snowsightでパイプ詳細を開くと、ステータス、保留中ファイル数、受信通知チャネル、定義SQL、権限、関係グラフなどを確認できます。
Copy Historyタブでは直近14日分の履歴と成功率、取り込みギャップ、最後の取り込みからの経過時間、保留中ファイルなどのメトリクスを確認できます。
こんにちは、DX攻略部のkanoです。 ダッシュボードの軽微な修正や、現場が使う簡単な業務アプリでも、外部ベンダー依頼だと見積もり調整や開発待ちが発生しがちです。 結果として「見たい指標が見られない」「改善の判断が遅れる」状態が[…]

コストとパフォーマンス
Snowflakeは適切な設定にすることでコストを抑えられるツールです。
Snowpipeに関しても設定次第でコストやパフォーマンスに影響が出るので、そのあたりに関してチェックしていきましょう。
Snowpipeのコストがかかるタイミングと節約
Snowpipeは取り込み処理に使われたサーバーレス計算の消費に応じて課金されます。
ファイルが到着していない待機時間は課金対象外ですが、失敗の再試行や不要な通知が多いと無駄な消費が増えます。
- 無駄な消費が増える典型例は極端に小さいファイルの大量投入、同一ファイルの重複通知、複雑な変換を伴うCOPY、エラー多発による再試行です。
- 節約の基本は対象を絞ることと再処理を減らすことです。ストレージ側のイベント通知はプレフィックスで対象パスを限定し、上流で簡易バリデーションを通過したファイルのみをステージに置きます。
- REST方式を使う場合も同様に、アプリ側で重複送信を避けるガードを入れ、失敗時のリトライ間隔と回数を適切に制御します。
レイテンシの目安とマイクロバッチ最適化
レイテンシはファイル形式やサイズ、COPYの変換有無などに影響されやすいです。
平均レイテンシは実データで計測し、ファイルの細切れ化や変換の複雑化を避けると安定します。
ファイルの大きさと本数に注意し、小さすぎるファイルを高頻度で送るとオーバーヘッドが支配的にならないようにしましょう。
ファイルサイズ設計と分割のベストプラクティス
適正サイズのファイルを短い間隔でステージングする運用が推奨です。
毎分のステージ投入を目安に、キュー管理と実ロードのリソース配分を最適化します。
- 目安は小さすぎず大きすぎないサイズで一定間隔にそろえることです。極端な小分けや単一の巨大ファイルは避けます。
- 取り込み間隔は短すぎても長すぎても非効率になりがちです。上流のエクスポートを調整し、一定周期で到着するように整えます。
- 圧縮は転送量の削減に有効ですが、圧縮方式はSnowflake側でサポートされる一般的な方式に統一し、パイプのファイルフォーマット設定と齟齬が出ないようにします。
- 形式は用途に合わせて選びます。ログやイベントはJSON→VARIANTで受け、後段で必要列に展開。データレイク由来のバッチはParquetやAvroで列型の利点を活かすと安定します。
こんにちは、DX攻略部のkanoです。 「Snowflakeについて調べていると、ウェアハウスという言葉がよく出てくるけど、これってなに?」 「ウェアハウスの仕組みや使う上でのポイントを知りたい」 Snowflakeの「ウ[…]

セキュリティと権限
ここではSnowpipeを安全に運用するために必要な権限の考え方を紹介します。
Snowpipeの権限は役割ごとに分けて考えると迷いません。見る、動かす、作るの三つに分け、必要最小限を割り当てることで、安全性を保ちながら日々の運用をシンプルにできるので参考にしてみてください。
必要な権限の全体像
Snowpipeを扱うには、まずデータベースとスキーマに対するUSAGEが土台になります。
取り込み先のテーブルにはINSERTを、内容確認を行う担当者にはSELECTも与えます。
ステージはUSAGEが必須で、内部ステージはREADやアップロードする場合はWRITEが必要です。
外部ステージはSnowflake側でUSAGEを付け、読み取り自体はクラウドの認証情報で許可します。
パイプそのものは、状態や履歴を確認するならMONITOR、停止や再開、手動ロードといった日常操作を行うならOPERATE、定義の変更や削除まで担うならOWNERSHIPを持たせます。
Snowsightで見えるようにするポイント
Snowsightでパイプを一覧できない時は、対象のデータベースとスキーマにUSAGEが付いているか、該当パイプにMONITORがあるかをまず確認します。
詳細画面は見えるのに操作ボタンが灰色のときはOPERATEが不足しています。
定義SQLを差し替えたいときはOWNERSHIPが必要です。
権限を付与したら、Snowsight上でロールを切り替えて画面を更新すると反映が早く確認できます。
外部ストレージ連携時の認可
外部ステージは二層で管理すると理解がスムーズです。
Snowflake側では外部ステージオブジェクトへのUSAGEを付け、クラウド側ではIAMロールやサービスアカウント、SASなどで読み取りを許可します。
自動インジェストを使う場合は、クラウドのイベント通知を作成できる権限も必要です。
ネットワークやリージョンのポリシーでイベントが使えない場合は、RESTでの通知に切り替えて同等の運用が可能です。
よくあるつまずきと対処
パイプが見つからない場合は、権限不足のほかにスキーマの選択違いもよくあります。
Snowsightの検索でパイプ名を入れて探すか、SQLでSHOW PIPESを実行すると所在の確認が早く進みます。
取り込みは動くのにテーブルの中身が見えない場合は、テーブルのSELECTが不足しています。停止や再開が実行できないときはOPERATEの不足が原因です。
外部ステージで読み込めない場合は、Snowflake側のUSAGEが足りていても、クラウド側の読み取り権限やイベント通知の設定が欠けていることがあります。
設定を直したら、Snowsightでパイプ詳細とCopy Historyを見比べ、失敗が解消しているかを確認すると安心です。
安定運用のベストプラクティス
Snowpipeは少ない設定でも動きますが、長く安定させるには最初の設計が肝心です。
ここでは日々のトラブルを避けつつコストと遅延を両立させるための実践ポイントをまとめます。
設計の原則を最初に決める
同じファイル群に対しては取り込み方式を一つに統一しましょう。
Snowpipeと一括COPYを混在させると重複取り込みや順序の乱れが起きやすく、原因調査も複雑になります。
用途や鮮度の要件が違う場合はプレフィックスで分け、パイプも分けて運用単位を明確にします。
ファイル命名とパス設計をそろえる
ディレクトリ構成は日付やデータ種別といった軸で切り、プレフィックスを見ただけで中身が想像できるようにします。
ファイル名にも生成時刻やソースシステムなどの情報を持たせると、Snowsightでの検索や異常時の切り分けが簡単になるのでおすすめです。
命名規則はチームで合意し、上流のエクスポート設定に組み込みます。
イベント通知は対象を絞り込む
自動インジェストを使うなら、ストレージ側のイベント設定で対象プレフィックスをきちんと絞ります。
関係のない領域からの通知が混ざると、キュー滞留や無駄な再試行が増えます。
アーカイブや一時領域は通知対象から外し、検証用のプレフィックスも本番とは分けておきましょう。
変更管理は小さく速く検証する
本番パイプを直接書き換えるのではなく、検証用のステージとプレフィックスで動作確認を行い、Snowsightのコピー履歴で期待どおりかを確かめてから本番に反映します。
定義の変更はリリースノート化して、上流の出力やダウンストリームの参照と整合するかをチームで確認すると安全です。
一括ロードとの使い分けを最後に確認する
一括COPYは大容量を決まったタイミングで取り込むのに向き、Snowpipeは到着次第に近い運用に向きます。
同じファイル群での併用は重複を招くため避け、要件ごとに対象を分けましょう。
片方に統一できない事情がある場合は、プレフィックスとテーブルを分けた上で監視と責任のラインを別にし、誤投入を物理的に防ぐ設計にします。
機能の違いで選ぶ
ここではSnowpipeを周辺機能と並べて眺め、要件に合う選択肢を一度で決められるように整理します。
ポイントは実行方式と遅延、運用のしやすさ、初期大量取り込みの有無です。
Snowpipeと一括ロード(COPY)の違い
Snowpipeはサーバーレスで新着ファイルを自動検知し、数分単位のマイクロバッチで取り込みを進めます。
ユーザーがウェアハウスを起動する必要はなく、パイプ詳細とコピー履歴で状態と直近の実績を確認できます。
到着頻度が高い小さなファイルや、随時反映したいログ系データに向いている点も重要です。
処理は並列で進むため厳密な順序保証はありませんが、ファイル名や時刻列で整合性を取る設計にすれば実務上は問題なく運用できます。
COPYはユーザーがウェアハウスを指定して明示的に実行する方式です。
毎日や毎時といった定期バッチ、大容量の初回取り込み、再処理のやり直しなど、開始と終了を自分でコントロールしたい場面に適します。
履歴はテーブル詳細のコピー履歴やワークシートの履歴関数で確認でき、ジョブ管理の都合に合わせて再実行しやすいのが利点です。
レイテンシはスケジュール次第で、Snowpipeのような到着即取り込みは行いません。
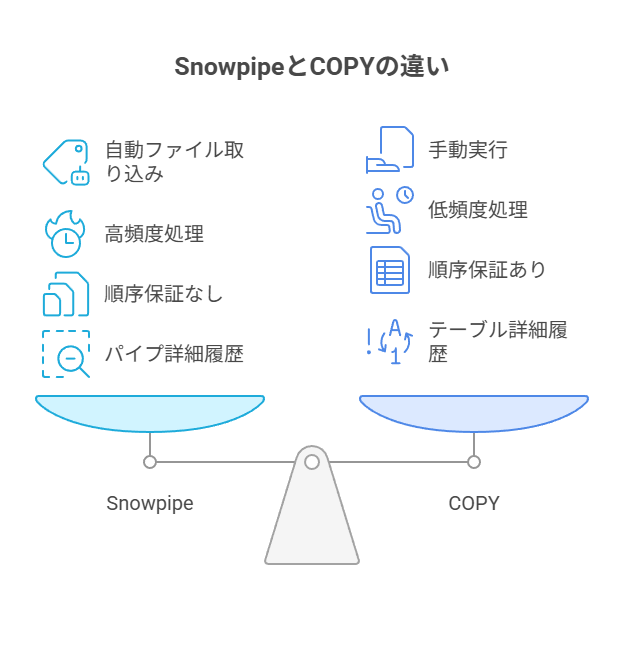
実務では、日常の更新はSnowpipeで自動化し、稀に発生する大規模なバックフィルやレイアウト変更の反映はCOPYで実行する、といった役割分担にすると運用がすっきりします。
同じファイル群で両方式を同時に使うと重複取り込みの原因になるため、プレフィックスやテーブルを分けて併用可否を明確にしておくと安全です。
SnowpipeとSnowpipe Streamingの使い分け
Snowpipeはファイル単位の取り込みを前提にしたマイクロバッチ方式です。
秒単位の低遅延は求めないが、数分で使えるようになれば十分という要件にうまくはまります。
導入の難易度も低く、ストレージイベントやREST通知を用意すれば動きます。
Snowpipe StreamingはSDKから行レベルで直接テーブルへ送る方式です。
到着から可視化までの遅延を極小化したいときに選択肢になります。
アプリ側にクライアント実装が必要になり、運用の責任範囲も増えますが、ファイル生成を待てないリアルタイム指向の要件に応えられます。
既存のバッチやファイル出力が前提ならSnowpipe、イベントストリームに近い更新で秒単位の反映が必要ならStreaming、と覚えておくと判断が速くなります。
Snowpipeはパイプ詳細とコピー履歴で取り込みの健康状態を見られ、Streamingはテーブルのメトリクスやワークシートのクエリで到達状況を確認します。
いずれの場合も、要件が混在するなら対象プレフィックスやテーブルを分け、運用や監視の単位を明確にすることが後々のトラブル回避につながります。
Snowpipeに関するよくある質問
Snowpipeを運用するときに出てくる疑問について、仕組みに即した注意点と現場で使える対処法を添えてまとめました。
取り込み順序は保証されるか
基本的には古いファイルから先に処理されますが、内部では並列で進むため厳密な順序の保証はありません。
イベントの届き方やファイルサイズのばらつきでも順番は前後します。
注意点は、レポートや下流処理をファイル到着順に依存させないことです。
そのための対処法として、時刻列や増分番号を必ず持たせ、取り込み後に並び替えるようにしましょう。
到着順が崩れると困る場合は一時テーブルに取り込んでから、時刻列や一意キーで整列して本テーブルへMERGEする運用が安全です。
重複や欠損をどう防ぐか
Snowpipeは取り込んだファイルのパスや名前を記録し、同じファイルの再取り込みを避けます。
ただし名前を変えて再配置された場合は別物として扱われます。
長く停止しているあいだに通知の保持期間を超えると取りこぼす可能性もあります。
注意点は上流のリトライや再出力でファイル名が変わるケースと、長時間の停止による通知欠落です。
対処法はファイル名に一意なIDやハッシュを含めること、テーブル側に業務キーやハッシュ列を持たせて重複を検知し弾くことです。
遅延到着や停止期間の補填は、期間を決めて手動ロードを行い、完了後に差分チェックを実施します。
Snowsightのコピー履歴で失敗や保留が偏っていないかを定期的に確認し、問題のあるプレフィックスは原因が解消するまで一時的に止めると拡大を防げます。
コストはどう見積もるか
課金は取り込み処理に使われたサーバーレス計算の消費に応じて発生します。
小さすぎるファイルの大量投入や、不要な再試行、複雑な変換は消費を押し上げる点に注意したいです。
極端に小さいファイルの連投と、エラーによる再試行の連鎖や、JSONの深い展開や多段の型変換も処理時間を増やします。
対処法は上流でファイルサイズと到着間隔をそろえることです。
形式と圧縮はパイプの設定と一致させ、COPYのオプションは必要最小限にします。
投入前に検証用プレフィックスで適合性を確かめてから本番へ切り替えると、失敗の再試行を減らせます。
運用ではコピー履歴の成功率、取り込みギャップ、保留中ファイルを定点観測し、値が悪化したときに見直す順番を決めておくと無駄な消費を抑えられます。
こんにちは、DX攻略部のkanoです。 Snowflake導入支援は「技術の穴埋め」ではなく、データ活用を事業の意思決定につなげるための投資を、短期間で軌道に乗せる手段です。 特に意思決定者が悩みやすいのは、導入そのものよりも「[…]

まとめ
SnowflakeのSnowpipeについて紹介しました。
Snowpipeはクラウドストレージの新着ファイルを検知して、サーバーレスで数分以内にテーブルへ取り込む継続的データ取り込み機能です。
自動インジェストとRESTの二方式に対応し、Snowsightのパイプ詳細やCopy Historyで健康状態と履歴を可視化できる点も注目の機能といえるでしょう。
ログやSaaSエクスポートのように小さなファイルが頻繁に届くケースで、取り込みの手動運用やバッチの遅延を解消するために活用してみてください。
DX攻略部で紹介している、その他のSnowflakeの記事も参考に、その機能をフル活用しましょう。
そして、DX攻略部では、Snowflake×Streamlitを活用した統合BI基盤構築支援サービスを行っていますので、Snowflake導入を検討している企業様はぜひDX攻略部にご相談ください!








