
こんにちは、DX攻略部のkanoです。
「SnowflakeのSnowparkで何ができるの?」
こういった疑問をお持ちではありませんか?
Snowparkは、Snowflakeの中でPythonなどのコードを動かし、データ変換から自動化、アプリ連携までを一気通貫で進められる仕組みです。
本記事では「業務で何に使えるのか」を先に整理し、次に「最小の作り方」と「運用でつまずかないコツ」までをつなげて説明します。
読み終える頃には、SQLだけで十分な範囲と、Snowparkを足すべき範囲が判断でき、社内で小さくPoC(概念実証:小さく試して効果を確かめること)を始められます。
途中でコストや権限設計の話も扱うので、現場だけでなく管理側の不安も一緒に潰していきましょう。
そして、DX攻略部では、Snowflake×Streamlitを活用した統合BI基盤構築支援サービスを行っています。
記事の内容を確認して、Snowflakeを自社に活用してみたいと考えた方は、下記のボタンをクリックしてぜひDX攻略部にご相談ください!
SnowflakeのSnowparkとは?
最初にSnowparkの基本概念と「なぜ使うのか」をまとめました。
SQL中心の運用に、Pythonなどの一般的な言語を安全に組み合わせられるという、Snowparkの強みについて確認していきましょう。
SnowflakeのSnowparkの基本概念(DataFrame API・UDF・UDTF・ストアド手続き)
Snowparkは、データを外に移動せずにSnowflake上で処理するための開発用ライブラリ(API)です。
Java、Python、Scalaで扱え、DataFrame API(表データを操作するための書き方)で変換処理を組み立てられます。

処理はSnowflake側で最適化されるため、大量データでも安定しやすい点が特徴です。
よく使うロジックは部品化でき、1行の入力に対し1つの値を返す関数はUDF(ユーザー定義関数)、1行から複数行を返す処理はUDTF(ユーザー定義テーブル関数)として定義し、SQLからも呼び出せるのも特徴です。
また、複数のテーブル操作やエラーハンドリングを含む一連の処理はストアド手続きにまとめると、再利用や保守が容易になる点もメリットと言えるでしょう。
実行基盤はSnowflakeの仮想ウェアハウス
Snowparkの実行基盤はSnowflakeの仮想ウェハウスです。
つまり、開発者はコードに集中しながら、スケールや同時実行性はウェアハウスのサイズと設定で制御できます。
データはSnowflake内にとどまり、ロールベースの権限、監査、データマスキングなどのガバナンスの枠内で実行されるため、社外システムにデータを持ち出すことなく高度な処理を実現できます。
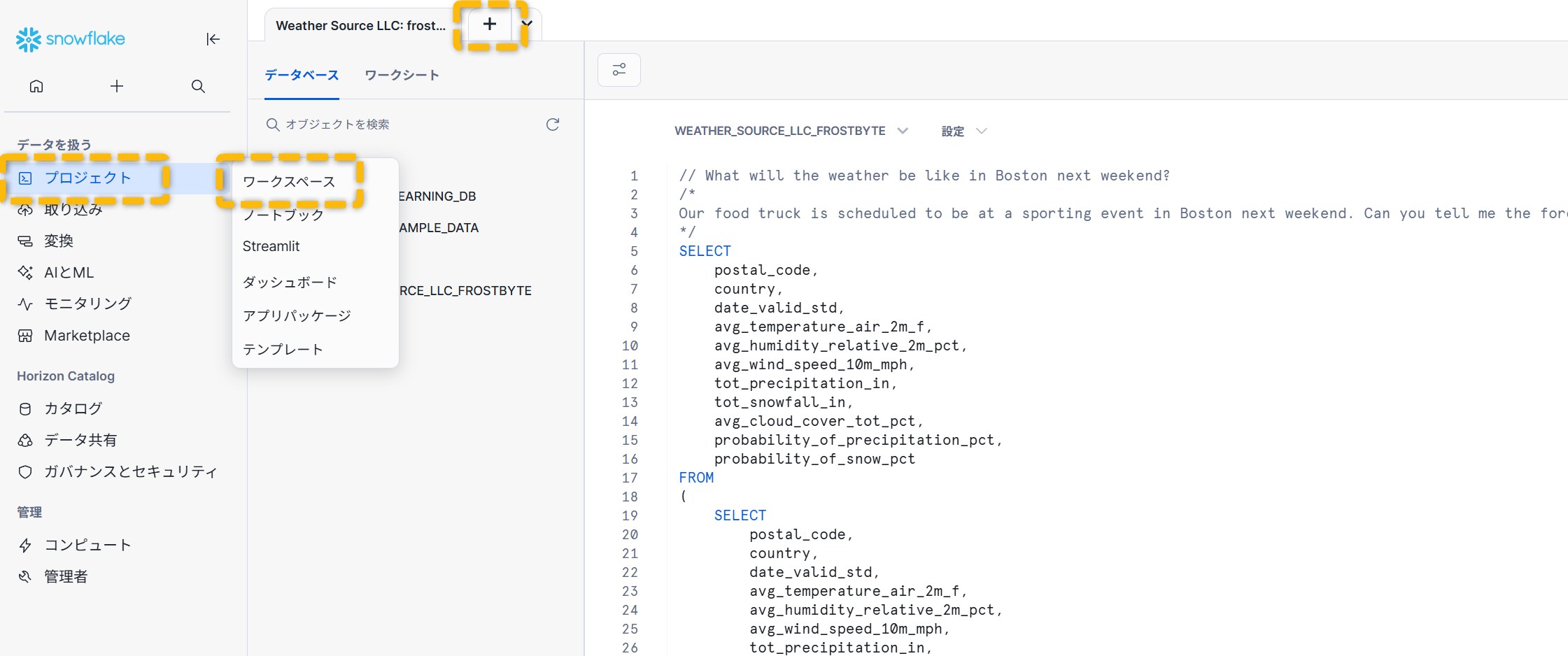
UIでは、左メニューの「プロジェクト」→「ワークシート」→「+」→「Pythonワークシート」から作成すれば、すぐにSnowparkコードを試せます。
- DataFrame API=表形式データをコードで扱うための書き方
- UDF=ユーザー定義関数(1行→1値の変換に最適)
- UDTF=ユーザー定義テーブル関数(1行→複数行を返す処理に最適)
- ストアド手続き=複数ステップの処理をまとめた再利用可能な手続き
どんなときにSnowflakeのSnowparkを使うべきか(SQLだけでは足りない場面)
Snowparkは「SQLだけでは表現しづらい」「外部ライブラリを使いたい」「前処理から学習・推論までをDWH内で完結したい」というニーズに最適です。
具体的には次のような場面で威力を発揮します。
複雑な前処理や条件分岐が多い処理
複雑な前処理や条件分岐が多い処理にSnowparkは有効です。
例えば、正規表現、テキスト前処理、カテゴリ変換、異常値処理など、SQLだけだと読みづらくなるロジックをコードで明瞭に表現したいときに活用しましょう。
機械学習の前段・推論を一気通貫で実行したい
特徴量生成を関数化し、学習済みモデルを使った推論をUDFとしてSQLから呼び出せます。
学習や再学習のバッチ実行はタスクでスケジュール化できます。
既存のPython資産を活かしたい
社内にある前処理関数やユーティリティをSnowflake側へ移し、データの近くで実行することで、データ転送の手間やセキュリティリスクを減らせます。
このように既存のPython資産を活かしたい場合に、Snowparkは有効です。
大きなデータを安定的に処理したい
ウェアハウスのサイズを調整するだけで処理能力を拡張でき、同時実行の設計も容易です。
結果キャッシュやマテリアライズドビューと併用するとさらに効率化できます。
業務ロジックを部品化して全社で再利用したい
UDF/UDTFやストアド手続きとして標準化し、SQLから呼べる形にすることで、BIや他チームにも横展開しやすくなります。
逆に、単純な集計や結合だけで完結する処理はSQLの方がシンプルで高速に書けます。
また、ミリ秒レベルの超低レイテンシのオンライン推論など、常時稼働のアプリケーション要件によっては別の実装方式を検討した方がよいケースもあります。
判断基準はシンプルで、「読みやすさ」と「再利用性」がSQLだけでは破綻しそうならSnowparkを足します。
具体的には、前処理の分岐が増えてSQLが長文化したとき、同じ変換を複数部署で使い回すとき、学習や推論をパイプライン化したいときが合図です。
逆に、単純な集計と結合だけならSQLのままが最短になります。
Snowflakeならではのメリット(Snowparkを選ぶ理由)
Snowparkの価値は「コードが書ける」こと自体ではなく、データガバナンス(権限や監査を含む統制)を崩さずに内製開発のスピードを上げられる点にあります。
たとえば、データを外部基盤へコピーせずに変換や推論を動かせるため、データ移動の手間や漏えいリスクを減らしやすくなります。
さらに、UDF(ユーザー定義関数)やストアド手続き(手順をまとめて実行する仕組み)として部品化でき、SQLから同じ形で呼べるので、運用の標準化にもつながります。
加えて、特殊な依存ライブラリが必要な場合でも、Snowpark Container Services(Snowflake内で管理されるコンテナ実行基盤)を使う選択肢があり、要件に応じた拡張が可能です。
こんにちは、DX攻略部のkanoです。 この記事は、はじめてSnowflakeを触る方が「最初の30分」で迷いやすいポイントだけを先回りして、最低限の動作確認まで進めるためのガイドです。 具体的には、Snowsight(Snow[…]

SnowflakeのSnowparkで「できること」早見表
Snowparkで実現できる代表的な機能領域を一覧で把握していきましょう。
| やりたいこと | Snowparkで使う要素(初出用語) | 最小の実装イメージ | 効果の目安(KPI例) |
|---|---|---|---|
| 複雑な前処理を読みやすくしたい | DataFrame API(表データ操作の書き方) | SQLで素材ビュー→Snowparkで分岐・文字列処理を実装 | 改修リードタイム短縮、属人化低下 |
| 変換を部品化して全社で再利用したい | UDF(ユーザー定義関数)、UDTF(ユーザー定義テーブル関数) | 共通関数をUDF化→SQLから呼び出し | 再利用率向上、バグ再発防止 |
| 差分処理を自動で回したい | Streams(変更検知)、Tasks(定期実行) | Streamsで差分→TasksでMERGEを定期実行 | 手作業ゼロ、更新遅延の削減 |
| 学習・推論をDWH内で回したい | Stages(ファイル置き場)、Tasks | 学習データ抽出→モデル保存→再学習を定期化 | 再学習頻度向上、運用工数削減 |
| 社内向けの簡易アプリを作りたい | Streamlit(簡易UI作成)、Snowpark | ボタン押下時だけSnowpark処理→結果表示 | 現場の自己解決率向上、依頼削減 |
この内容を確認することで、どの場面で効果が出るかを素早く見極めるのに役立ちます。
データ前処理・変換(ETL/ELT)をコードで内製化
ETLやELTは「取り込み→整形→格納」のことです。
SnowparkではDataFrame APIという表を扱う書き方で、不要列の削除、条件に合う行だけの抽出、別テーブルとの結合、集計、日付の整形などを読みやすいコードで表現できます。
処理はSnowflake側で最適化されるため、大きなデータでも安定して実行できます。
ポイントは、SQLと併用できることで、単純な集計はSQLで、複雑な前処理はSnowparkで、と役割分担すると可読性と性能の両方を取りやすくなります。
Snowsightの「プロジェクト→ワークシート」でコードを書いて実行し、結果プレビューを見ながら少しずつ整えていくのが始めやすい進め方です。
特徴量生成・データクレンジングの定型化
機械学習で使う入力列を「特徴量」と呼びます。
欠損値の補完、外れ値の扱い、正規化、カテゴリ変換など、毎回似たような処理を行うなら、関数としてまとめておくと再利用が簡単です。
SnowparkならUDFやストアド手続きにしておけるので、誰が実行しても同じ結果になり、品質のばらつきを防げます。
「毎日9時に最新データで特徴量を再計算する」といった定期運転も、後述のTasksと組み合わせれば自動化できます。
これにより、学習や推論に常に新鮮な特徴量を渡せます。
機械学習の学習・推論パイプライン構築
学習データの抽出、特徴量生成、モデル学習、モデル保存、そして新しいデータへの推論までをSnowflake内で完結できます。
推論はUDFとして公開すれば、BIや他システムからもSQL一発で呼び出せます。
リアルタイム性がそこまで必要ない業務(スコア更新が数分〜数十分単位で十分なケース)では、バッチ推論にして結果テーブルを用意すると運用が安定します。
モデルファイルはステージに保存してバージョン管理し、再学習はTasksでスケジュール化しておくと安心です。
バッチ処理と準リアルタイム処理(StreamsとTasksの活用)
Snowflakeのバッチは「決まった時間ごとにまとめて処理」、準リアルタイムは「短い間隔でこまめに処理」を意味します。
Snowflakeでは、テーブルの変更差分を捕まえるのがStreams、定期実行や依存関係管理をするのがTasksです。
例えば、受注テーブルの新規行だけをStreamsで拾い、30分ごとにTasksで集計テーブルへ反映します。
こうすると全件再処理せずに済み、コストも時間も節約できます。
Snowsightの「タスク」画面でスケジュールや依存関係の可視化、実行履歴の確認ができるため、運用監視もUIだけで完結します。
再利用可能な処理の部品化(UDF/UDTF/ストアド)
Snowparkでよく使うロジックは部品化すると強いです。
1行から1つの値を返す処理はUDF、1行から複数行を返す処理はUDTF、複数ステップの一連処理はストアド手続きにまとめます。
部品化の利点は三つあり、第一に再利用性が上がること、第二にテストしやすく品質を保てること、第三にSQLからも呼べるため、データアナリストやBI担当にも展開しやすいことです。
レビューのしやすさや変更の影響範囲の把握もしやすくなるので、ぜひ活用してみてください。
外部サービスやデータとの連携(外部関数・ステージ・Marketplace)
外部ストレージ(S3やGCS、Azure)を「外部ステージ」として登録すれば、ファイルの取り込みや書き出しがスムーズになります。
到着次第自動で取り込む「Snowpipe」と組み合わせれば、手動オペレーションを減らせます。
自社APIやSaaSを呼びたい場合は「外部関数」で連携できます。住所の正規化、外部スコア付与、翻訳など、外のサービスを呼んで結果を取り込むイメージです。
さらに「Marketplace」では第三者データを安全に参照でき、天候、地理、企業情報などをすぐに分析へ活用できます。
データアプリのバックエンド処理
Snowparkはデータ処理の心臓部として、Streamlitアプリなどの見える化と相性が良いです。
Snowflakeにログインしたユーザーだけが使える内製ツールを素早く用意でき、権限や監査もSnowflake側の仕組みに乗せられます。
たとえば「営業が指定期間を選ぶ→Snowparkが集計→グラフで表示」といった簡易アプリなら、Snowsightから作成して同じウェアハウスで動かせます。
長時間開きっぱなしだとコストが増えるため、使い終わったら閉じる、処理はボタン押下時だけ実行するなどの工夫が有効です。
コスト最適化とパフォーマンス最適化の余地
Snowflakeのコストは主にウェアハウスの実行時間で決まります。
無駄を抑える基本は、ウェアハウスの自動サスペンドと自動再開の設定、サイズの適正化、ジョブの分割と並列化です。
性能面では、結果キャッシュの効く形でクエリを組み立てる、重い処理は事前にマテリアライズドビューで用意する、I/Oが多い処理は列指向を意識したデータ型にする、などが効きます。
運用ではSnowsightの「クエリ履歴」や「ウェアハウス設定」でボトルネックを把握し、必要に応じてリソースモニタやタグでコストの見える化を行うと、チーム全体で最適化を回しやすくなります。
こんにちは、DX攻略部のkanoです。 ダッシュボードの軽微な修正や、現場が使う簡単な業務アプリでも、外部ベンダー依頼だと見積もり調整や開発待ちが発生しがちです。 結果として「見たい指標が見られない」「改善の判断が遅れる」状態が[…]

データ加工・パイプラインをSnowflakeのSnowparkで組む
この章では、日々の業務で必ず発生する「データを整える」「定期的に回す」を、SnowflakeとSnowparkでどう形にするかを解説します。
目的は2つで、第一に、レポートやダッシュボードが常に最新・正確な状態になることです。
そして、第二に、人手の作業や属人化を減らし、手戻りやトラブルを防ぐことです。
ここで紹介する型を参考にすると、小規模チームでも短期間で「止まらないデータ更新」に近づけます。
まずは日次か時間ごとの小さな処理から自動化し、うまく回る形を社内標準にしていきましょう。
DataFrame APIでの変換とSQLの書き分け
DataFrame APIでの変換とSQLの書き分けに対して、「なぜ使い分けるの?」と疑問を抱くかもしれません。
この使い分ける理由は、読みやすさと最適化のバランスを取るためです。
単純な集計・結合・フィルタはSQLが速く書け、Snowflakeの最適化も効きやすいです。
逆に文字列処理や分岐が多い前処理、外部ライブラリを使いたい処理はsnowparkのDataFrame APIが明快です。
実務では「上流はSQLでビュー化→下流の複雑処理はsnowparkで仕上げる」という分担が扱いやすく、後から見返したときに“どこで何をしているか”が追いやすくなります。
日本語UIでは左メニューの「プロジェクト→ワークシート」からPythonワークシートを作成し、次のような最小コードで手を動かしましょう。
import snowflake.snowpark as snowpark
from snowflake.snowpark.functions import col
def main(session: snowpark.Session):
# 例: 製品別の売上トップ5を計算
sales = session.table("APP.SALES")
top5 = (sales
.group_by("PRODUCT_ID")
.agg({"AMOUNT":"sum"}) # 合計売上
.sort(col("SUM(AMOUNT)").desc()) # 大きい順
.limit(5))
return top5このコードは「読みやすい処理の流れで書ける」「実行時はSnowflake側がSQLに最適化してくれる」がポイントです。
まずはSQLで素材のビューを作り、snowparkで仕上げをする、という分担を習慣化しましょう。
スキーマ設計と依存関係管理
品質と変更耐性を高めるためにRAW(生データ)→STG(整形)→DWH(分析用)のように層を分け、依存関係を明確にしましょう。
- RAW(生データ): 取り込んだまま。手を加えないありのまま。
- STG(整形): 型や列名をそろえ、欠損や重複を処理した使える素材。
- DWH(分析用): 事業指標や集計ビュー、下流アプリが直接使う完成品。
層を分けると、上流の変更があっても下流への影響範囲を限定でき、原因調査も短時間で済みます。
命名規約と権限(ロール)を合わせて定めると運用が安定するので、ルール化しておきましょう。
タスクスケジューリングと監視(Tasks/Streams)
早く・安く・安全に回すために、Snowsightの「Tasks」画面でスケジュールと依存を設定し、「Data>Databases」でStreamsの差分状態を確認しましょう。
-- 変更された行だけを追跡するストリーム
create or replace stream STG_ORDERS_CHG on table STG.ORDERS;
-- 30分ごとに差分をDWHへ反映するタスク
create or replace task TASK_UPSERT_ORDERS
warehouse = ETL_WH
schedule = 'USING CRON 0,30 * * * * Asia/Tokyo'
as
merge into DWH.ORDERS d
using (select * from STG_ORDERS_CHG) s
on d.ID = s.ID
when matched then update set d.* = s.*
when not matched then insert (select * from s);「受注の新規・更新だけを拾って集計テーブルへ反映」を、30分に一度回す例です。
差分だけ処理するので無駄が少なく、障害時も実行履歴からどこで止まったか追いやすい形です。
こんにちは、DX攻略部のkanoです。 顧客データを活用したマーケティングは「つなぐ力」で成果が大きく変わります。 Snowflakeはデータのサイロを解消し、分析と配信の両方に耐える柔軟な基盤を提供するツールです。 顧客デー[…]

Snowparkを機械学習・生成AIで活用する
この章では、学習と推論をSnowflake内で閉じる設計と、生成AIを組み合わせる入口を説明します。
Snowparkを使って、データ前処理、特徴量生成、学習・推論のロジックをコードで書いてSnowflake内で実行していくイメージです。
学習フローの実装(学習データ抽出〜モデル管理)
Snowparkを使って、学習データはSQLやDataFrameで抽出し、特徴量生成を関数化します。
モデルはステージに保存してバージョン管理し、再学習ジョブはTasksで定期実行するのが基本です。
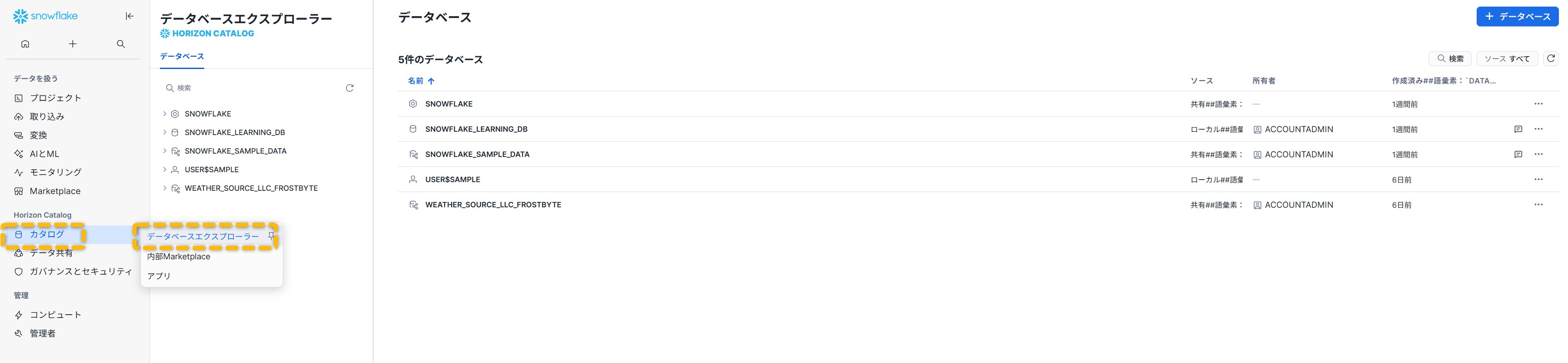
モデルやファイルは、左メニューの「カタログ(またはデータ)」からデータベースエクスプローラーを開き、対象のデータベースとスキーマを選んで「Stages」タブを表示すると確認できます。
初回は「ディレクトリテーブルを有効化」を押し、ウェアハウスを選んで更新するとファイル一覧が見られます。
内部ステージへのアップロードは「取り込み→データの追加→ステージにファイルをロード」から行いましょう。
本番推論の実装と運用(UDF/パイプライン化)
snowparkで推論処理をUDFやストアドにして、定期タスクで実行します。
軽量モデルはUDFに組み込み、SQLで一括推論できるのでおすすめです。
重いモデルはバッチ推論にして、結果テーブルをBIに渡すと安定するので、レイテンシ要件が厳しい場合は疎通確認やウォームアップを考慮してください。
GPUが要る、常時待ち受けたいといった要件では、コンテナ実行機能でモデルサービングを構築し、snowparkや外部関数から呼ぶ設計が向きます。
こんにちは、DX攻略部のkanoです。 企業のDX推進では「データを集められるか」だけでなく、「意思決定に使える状態にできるか」が成果を左右します。 ところが現場では、部門ごとにデータが分断され、集計に時間がかかり、結局は経験と勘に戻っ[…]

データアプリケーション開発
Snowflakeの中で完結する軽量バックエンド+簡易UIの作り方を紹介します。
狙いは「データを動かす処理(集計・前処理・推論)をsnowparkで書き、結果をアプリやBIから安全に使える形にする」ことです。
まずは社内向けの小さな業務ツールを素早く提供するところから始めていきましょう。
バックエンド処理をSnowflakeのSnowparkで実装する流れ
ここでは「なにを、どこに、どう置くか」が要点です。最短ルートは次の5ステップです。
-
データモデルを決める
入力テーブル(RAW/STG)と、アプリやBIが読む出力テーブル・ビュー(DWH)を紙に描きます。誰が何を見て、どの粒度で更新するかを先に決めると迷いません。 -
素材はSQL、仕上げはsnowpark
単純な結合・集計はSQLビューで“素材”を用意し、文字列処理や分岐が多い“仕上げ”はsnowpark(Pythonなど)で書きます。可読性と性能の両立がしやすくなります。 -
ロジックは部品化(UDF/ストアド)
よく使う前処理やルールはUDF/UDTFやストアド手続きにして再利用します。SQLからも呼べるので、アプリ以外(レポート・他チーム)にも展開しやすくなります。 -
アプリ(可視化・操作)を用意
Snowsightの左メニューから新規のStreamlitアプリを作成し、上述の出力ビューを読み込んで表やグラフ、ボタン実行を配置します。ボタン押下でsnowpark処理を呼ぶ設計にすると、利用時だけ計算が走るのでコストを抑えやすいです。 -
定期実行と監視
夜間の更新や毎時集計はタスクに登録して自動化します。依存関係(例: 特徴量→集計→出力ビュー)を順番に定義しておくと、事故が起こりにくく、復旧も簡単です。
5つのステップは、言い換えるならば「データの加工や計算の中身をPythonなどで書いてSnowflake内で安全に実行し、その結果をアプリやBIが使える形で渡す一連の段取り」といった感じです。
つまり、中身の計算はsnowpark(コード)、呼び出し・配布はSQL(テーブル/ビュー)、運転はタスク/ストリーム、見張りは権限とガバナンスというイメージになります。
この型にすると、データ処理が再現可能・自動・安全になり、少人数でも安定して“動くバックエンド”を保てます。
セキュリティと権限(最小権限・データガバナンス)
見せて良いものだけ見せる・触って良いところだけ触れるを、Snowflake標準機能でシンプルに実現する要点だけを押さえます。
「最小権限」の原則でロールを設計し、行アクセス/列マスクのポリシーを適用しましょう。
タグで機密区分を可視化しておくと管理が楽になります。
こんにちは、DX攻略部のkanoです。 Snowflakeの導入や活用を外部コンサルに頼るべきか、どのように契約し何を成果物として受け取り、どんなKPIで評価すればよいか、初めてだと判断が難しいポイントが多いものです。 本記事で[…]

運用・ガバナンスとコスト設計
ここでは、Snowflakeを日常運転で安定させつつ無駄な費用を抑えるための基本設計をまとめます。
権限/ロール設計と監査
運用事故を防ぎつつ運転スピードを落とさないために、最小権限と役割分担を徹底します。
そのためには、ロールを役割で分けることが重要です。
例えば、 開発者用、運用用、アプリ閲覧用など。書き込み系(INSERT/UPDATE/CREATE)は必ず別ロールに分離しましょう。
また、付与は最小限に: DB/スキーマ/ウェアハウスのUSAGE、読み先テーブルのSELECTなど必要なものだけし、一括付与より対象を限定すると安全です。
ウェアハウス設定・キャッシュ活用・並列度の考え方
速さとコストのバランスは、ウェアハウスとキャッシュの設計で決まります。
自動サスペンド/自動再開は必須で、この機能を使うことで 待機コストをゼロにできるのです。
その際の設定目安は1〜5分でサスペンドにして、無駄なコストを抑えましょう。
ウェアハウスの設定は、小さく始めて、待ち行列(キュー)や実行時間を見ながら段階的に上げ、重いバッチは専用ウェアハウスに分離するのがおすすめです。
こんにちは、DX攻略部のkanoです。 「Snowflakeについて調べていると、ウェアハウスという言葉がよく出てくるけど、これってなに?」 「ウェアハウスの仕組みや使う上でのポイントを知りたい」 Snowflakeの「ウ[…]

他機能との連携ポイント
Snowparkの処理を支える周辺機能を「入れる」「流す」「広げる」の3視点でやさしく説明します。
具体的にはデータの取り込み、差分の自動処理、第三者データの活用を日本語UIでの操作イメージと一緒に押さえます。
Snowpipe・外部ステージでのデータ取り込み
Snowpipe・外部ステージでのデータ取り込みを実行し、「外からSnowflakeへデータを入れる」流れを確認しましょう。
まずファイルの置き場所であるステージを用意し、次にSnowpipeで到着したファイルを自動でテーブルへ取り込みます。
UIの入り口は次のどちらかで、環境により表記が違うことがあります。
- カタログ→データベースエクスプローラー→対象データベース→スキーマ→Stages
- データ→データベース→対象データベース→スキーマ→Stages
実際の流れは以下のようになります。
-
ステージを作る(内部ステージはSnowflake内、外部ステージはS3/GCS/Azureに接続)
-
ファイルを置く(内部ステージはUIからアップロード可。外部ステージはクラウド側に配置)
-
Snowpipeを作る(ファイル到着を検知して自動でCOPY実行)
最小のサンプルとして、以下の形を参考にしてみてください。
create or replace stage ext_s3
url='s3://my-bucket/path/';
create or replace pipe p_orders as
copy into RAW.ORDERS
from @ext_s3
file_format=(type=csv skip_header=1);運用のコツとして、「人が来たら手動でロード」から「置いたら自動で反映」へ置き換えるとミスと待ち時間が減ります。
また、初回はステージでディレクトリテーブルを有効化すると中身をUIで確認しやすくなるのでおすすめです。
Streams/Tasksでの変更データ処理
Streamsはテーブルの差分だけを覚えておき、Tasksは「いつ」「どの順番で」実行するかを管理します。
全件を毎回やり直さずに済むので速くて低コストです。
タスクは左メニューの「モニタリング」から「クエリ履歴」、「タスク履歴」などから確認しましょう。
最小サンプルは以下のような形です。
create or replace stream STG_ORDERS_CHG on table STG.ORDERS;
create or replace task TASK_UPSERT_ORDERS
warehouse = ETL_WH
schedule = 'USING CRON 0,30 * * * * Asia/Tokyo'
as
merge into DWH.ORDERS d
using (select * from STG_ORDERS_CHG) s
on d.ID = s.ID
when matched then update set d.* = s.*
when not matched then insert (select * from s);差分だけ処理するので速い、安い、壊れにくいの三拍子が揃った形です。
実行履歴をUIで追えるので失敗時の原因特定が容易というのも、大きなメリットといえるでしょう。
Marketplace/共有データの活用
Marketplace/共有データの活用を確認しておきましょう。
SnowflakeのMarketplaceは、天気や企業属性などの第三者データやデータアプリをコピー不要の安全な共有参照で素早く使えるデータのアプリストアです。
Marketplaceでは天候や地理、企業属性などの第三者データをコピーせずに参照できます。
提供側が更新すると利用側にも即反映され、鮮度を保ったまま分析に使えます。
- 在庫や販売と天候データを組み合わせて需要予測精度を上げる
- 自社CRMに企業属性データを紐づけてセグメントの精緻化を行う
- コピーではなく共有参照なので、不要な二重保管や同期作業が発生しません
取り込みはSnowpipeで自動化し、RAWに集約しましょう。
また、外部データはMarketplaceで共有参照し、鮮度とガバナンスを両立することが重要です。
こんにちは、DX攻略部のkanoです。 「SnowflakeのMarketplaceって何?」 「どうやって使うの?」 Snowflake Marketplaceは、データや機能、アプリを『探す→契約する→すぐ使う』までを[…]

よくある質問(FAQ)
この章では、導入時によく出る疑問に一問一答で答えます。
迷ったらここに戻って確認しましょう。
SQLだけで組むのと何が違うのか?
SQLは宣言的で最適化されやすい一方、複雑な前処理や外部ライブラリを使う処理は記述が難しくなります。
Snowparkを併用すると、Pythonなどで柔軟にロジックを書け、処理はSnowflake内で安全に実行されます。
Sparkやdbtとどう使い分けるのか?
大規模な分散処理や既存のSpark資産があるならSparkを継続し、DWH内で完結させたい前処理や推論はSnowparkが適します。
dbtはSQL中心の変換管理に強く、Snowparkは言語でのロジック表現に強いので併用も一般的です。
料金はどこで増えるのか?抑えるコツは?
主にウェアハウス実行時間とサーバーレス機能(例: 取り込みやAI機能)が料金に関わってきます。
自動サスペンド、バッチの並列・分割、キャッシュとマテビュー活用、長時間接続のアプリを閉じるなどで抑制できるので、使い放しにならないようにしましょう。
権限設定で最初に詰まりやすいポイントは?
ロール(役割)を「開発」「運用」「閲覧」で分け、書き込み系権限を分離します。
まずはUSAGEとSELECTから始め、必要になったら段階的に付与すると事故を減らせます。
コストが急に増えるのはどんなとき?
ウェアハウスの実行時間が延びるケースと、サーバーレス系機能を使い放しにするケースが典型です。
自動サスペンドと、処理の専用ウェアハウス分離、アプリの開きっぱなし回避をセットで徹底しましょう。
こんにちは、DX攻略部のkanoです。 「Snowflakeの見積もりを作ろう」と思った瞬間に、手が止まるケースは少なくありません。 料金体系が複雑に見えたり、利用部門の要望が固まっていなかったり、契約条件や運用ルールが未確定で、試算が[…]

まとめ
SnowflakeのSnowparkで実務的に「何ができるのか」という点について紹介しました。
Snowparkを活用することで、DataFrameでの変換、Streams×Tasksの自動化などを、すべてをSnowflake内で完結できます。
つまり、データを外に出さずにPythonなどで処理の中身を書き、SQLやタスクと組み合わせて再現可能かつ自動で運用できるのが最大の強みです。
DX攻略部で紹介している、その他のSnowflakeの記事も参考に、その機能をフル活用しましょう。
そして、DX攻略部では、Snowflake×Streamlitを活用した統合BI基盤構築支援サービスを行っていますので、Snowflake導入を検討している企業様はぜひDX攻略部にご相談ください!







