
こんにちは、DX攻略部のkanoです。
Snowflakeの運用で怖いのは、「気づいたときには請求が跳ねていた」という予算超過です。
特に部門利用が広がるほど、原因が見えにくくなり、止血も再発防止も後手になりがちです。
コストの増大は「事業の成長」の証である場合も多く、重要なのは、「何にいくら投資され、それが予算内であるかを常に可視化できていること」にあります。
この記事では予算超過が起きる典型パターンを整理し、事前検知の観測ポイント、アラート設計、運用の作り方までを一本道で解説します。
経営・管理側の観点でも説明しやすいよう、効果(コスト/リスク)、期間、体制の見取り図も織り込みます。
そして、DX攻略部では、Snowflake×Streamlitを活用した統合BI基盤構築支援サービスを行っています。
記事の内容を確認して、Snowflakeを自社に活用してみたいと考えた方は、下記のボタンをクリックしてぜひDX攻略部にご相談ください!
Snowflakeで予算超過が起きる典型パターン
この章では、予算超過が起きやすい「ありがちな原因」を先に把握します。
原因が分かると、見るべき指標と止血策が決まりやすくなります。
| 発生パターン | 主な原因 | 経営上のリスク | 対策の方向性 |
| リソースの放置 | ウェアハウスの停止忘れ | 無駄な固定費の発生(ROI低下) | 自動停止設定の徹底 |
| 非効率な処理 | 重いクエリ・環境分離不足 | 特定部門による予算の食いつぶし | クエリ監視と計算リソースの制限 |
| 需要の急増 | 利用ユーザー・ツール増 | 予実管理の乖離 | 段階的アラートによる早期検知 |
ウェアハウスの使いっぱなし(停止忘れ、常時稼働)
よくある課題は、仮想ウェアハウス(クエリ実行に使う計算リソース)が止まらず、静かにクレジットを消費し続けるケースです。
開発や検証で一度起動し、そのまま放置されると、数日単位で積み上がります。
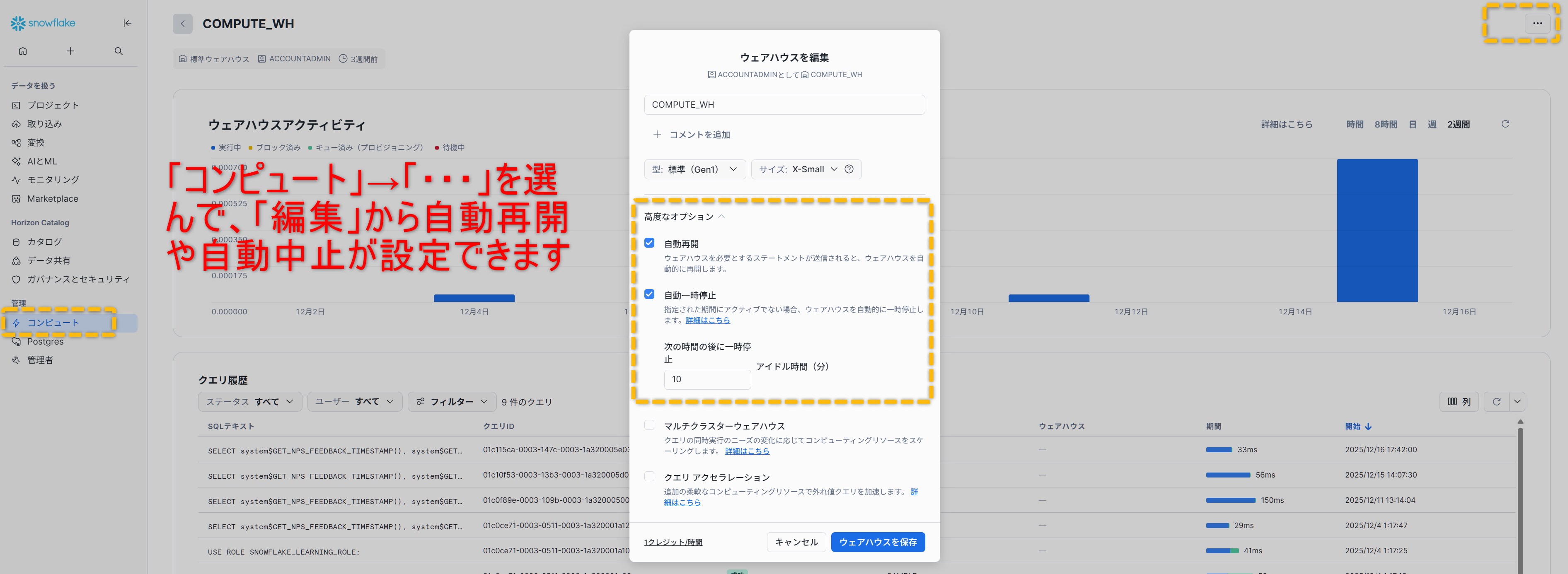
解決アプローチは明快で、自動中断(AUTO_SUSPEND)を徹底し、必要なときだけ自動再開(AUTO_RESUME)で動かす運用に寄せます。
加えて「誰が使うウェアハウスか」を命名規則で明確にし、放置が見つかる状態を作りましょう。
実務では、開発用は自動中断を短め、本番は業務影響を見ながら現実的な値に設定するのが進めやすいです。
まずは「使いっぱなしをゼロにする」だけでも、予算の変動幅が小さくなります。
こんにちは、DX攻略部のkanoです。 「Snowflakeについて調べていると、ウェアハウスという言葉がよく出てくるけど、これってなに?」 「ウェアハウスの仕組みや使う上でのポイントを知りたい」 Snowflakeの「ウ[…]

想定外に重いクエリ(結合、ソート、フルスキャン)
課題は、少数のクエリが予算を一気に溶かすパターンです。
結合(JOIN)や並べ替え(ORDER BY)、フルスキャン(全件走査)が重なったり、必要以上に広い期間・列を読んだりすると、実行時間が伸びやすくなります。
解決アプローチとしては、クエリ履歴(Query History)で「実行時間が長い」「スキャン量が大きい」ものを特定し、対象期間を絞る、不要な列を減らす、集計粒度を落とすなどの応急対応から入るのが安全です。
実務イメージとしては、まず上位数本の高コストクエリを直すだけでも効果が出ます。
全体最適にこだわるより、火元を潰す順番で進めるほうが短期間で結果につながります。
並列実行の増加(同時利用、バッチ集中)
課題は、同時にたくさんの処理が走ることで、ウェアハウスが忙しくなり、実行時間が伸びたり、マルチクラスターウェアハウス(同時実行をさばくためにクラスターを増やす機能)が増えたりするケースです。
朝のダッシュボード更新、夜間のバッチ、全社の分析が同時刻に集中すると起きやすくなります。
解決アプローチは、ピーク時間をずらす、処理を分割する、ウェアハウスを用途別に分けることです。
用途別に分けると、どの業務がコストを使っているかも見えやすくなります。
実務では「バッチは夜間」「全社集計は朝一」などの暗黙ルールが事故を招くため、実行タイミングを棚卸しして衝突を避けるだけでも改善できます。
新規ツール・新規ユーザー追加による負荷増
課題は、BIツール(ダッシュボード)やETL(データを取り出し・加工し・取り込む処理)を追加したタイミングで利用が跳ねることです。
特にキャッシュが効かないクエリが増えると、予算が読めなくなります。
解決アプローチとしては、導入時に「どのウェアハウスで動かすか」「どの頻度で更新するか」「上限をどこに置くか」を決め、予算超過の事前検知とセットでローンチします。
実務では、ツール導入の承認フローに「コスト見積もり」「アラート設定」「責任者」を含めると、後から揉めにくくなります。
開発環境が本番並みに回っている(環境分離不足)
課題は、開発・検証のつもりが、いつの間にか本番と同等のデータ量・頻度で回り続ける状態です。
環境が分離されていないと、止める判断も難しくなります。
解決アプローチは、環境分離(開発/検証/本番)を前提に、開発側には強めのガードレール(予算上限や停止ルール)を置くことです。
実務イメージとしては、まず「開発は小さめのウェアハウスしか使えない」「一定額を超えたら自動停止」まで決めると、予算超過のリスクが大きく下がります。
こんにちは、DX攻略部のkanoです。 Snowflakeの料金体系は、料金表を読むだけでは腹落ちしにくいのが正直なところです。 なぜなら費用が「保存(ストレージ)」「計算(コンピュート)」「データ転送」という使い方の結果で決ま[…]

事前検知の前に押さえるべきコストの見方
この章では、Snowflakeのコストを「請求書が来てから見る」のではなく、「兆しを早くつかむ」ための見方に変えます。
ここが揃うと、事前検知が設計しやすくなります。
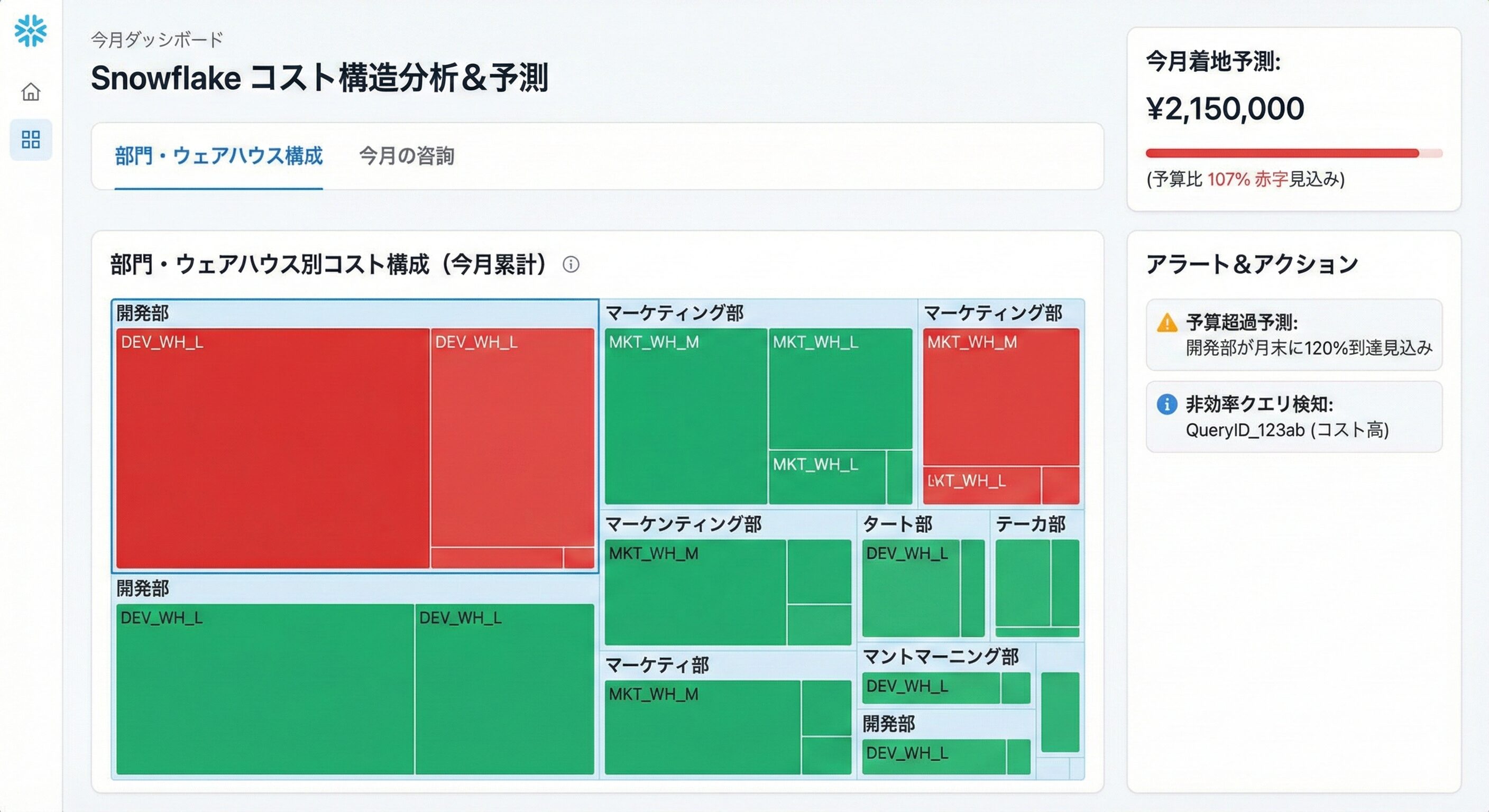
※上記画像はイメージ図であり、実際のSnowflakeのダッシュボード画面ではありません。
クレジット課金の基本(どこで増えるか)
Snowflakeのコストは、主に仮想ウェアハウスの稼働(計算処理)でクレジットが消費され、データの保管(ストレージ)でも費用が発生します。
予算超過が起きやすいのは、多くの場合「計算処理の使いすぎ」です。
つまり、事前検知の中心は「どのウェアハウスが」「いつ」「どれだけ動いたか」を追うことになります。
ここを押さえるだけで、原因の切り分けが一気に進みます。
誰が、どのウェアハウスで、いつ使ったかの切り分け
予算超過の現場では「全体が増えた」状態から始まります。
そこで、切り分けの軸を固定しましょう。
おすすめは、ウェアハウス別→時間帯別→実行主体(ユーザー/ロール)別の順番です。
この順番にすると、止血が必要な範囲を狭めやすく、関係者への連絡も短く済みます。
経営・管理側への説明でも「どの業務が増えたか」に直結するため、合意を取りやすくなるでしょう。
請求額ではなく「利用の兆し」を早く見る考え方
事前検知は、月末の請求額ではなく「日次」「時間帯」の変化を見る発想です。
例えば「昨日より急に増えた」「特定の時間帯だけ跳ねた」「特定ウェアハウスだけ増えた」といった兆しを拾います。
この兆しが拾えれば、同じ月内でも早い段階で手が打てます。
こんにちは、DX攻略部のkanoです。 「Snowflakeを導入したけど、思ったよりコストがかかっていた」 「もう少しSnowflakeの料金を節約したい」 こういった悩みを持つ方も多いかもしれません。 Snowf[…]

予算超過を事前検知するための観測ポイント
この章では「何を見れば事前に気づけるか」を具体化します
観測ポイントを絞ることで、監視が形骸化しにくくなるので確認していきましょう。
ウェアハウス別の利用推移を追う
最初に見るべきはウェアハウス別の推移です。
ウェアハウスは用途別に分けられるため、コストの責任範囲を切りやすいからです。
運用では、主要ウェアハウスについて「日次のクレジット消費」「ピーク時間帯」「前週平均との差分」を定点観測しましょう。
異常が出たら、次のステップでクエリと実行主体に降りていきます。
クエリ履歴から高コスト要因を見つける
次に、クエリ履歴で高コスト要因を特定します。
解決アプローチとして、まずは上位数本に絞り、実行時間が長いもの、スキャンが大きいものを優先します。
応急対応で効果が出たら、恒久対応(集計テーブル化、実行頻度見直し、運用時間帯の変更)へ進みましょう。
実務では、クエリタグ(クエリに付けるラベル)を使うと「この処理はどのジョブか」が追いやすくなり、原因特定が速くなります。
ユーザー・ロール別の利用増加を検知する
ウェアハウスとクエリが分かっても、実行主体が分からないと対応が遅れます。
そこで、ユーザーやロール(役割)別の利用増加も観測します。
例えば「特定ロールだけ急増」「新規ユーザーが大量実行」などが見えると、連絡先と初動が決まります。
統制の観点でも、権限設計(誰が何を実行できるか)を見直すきっかけになります。
バッチ処理・定期処理の増加を見逃さない
予算超過は、定期処理の追加や頻度変更でも起きます。
課題は「いつ変わったか」が分からないことです。
解決アプローチとして、ジョブの棚卸し(いつ、何が、どのウェアハウスで動くか)を作り、追加・変更があったら監視対象に自動で乗るようにします。
最初は手作業でも構いません。変更点が追えるだけで、事前検知の精度が上がります。
こんにちは、DX攻略部のkanoです。 企業のDX推進では「データを集められるか」だけでなく、「意思決定に使える状態にできるか」が成果を左右します。 ところが現場では、部門ごとにデータが分断され、集計に時間がかかり、結局は経験と勘に戻っ[…]

アラート設計の基本(予算超過を未然に止める)
この章では、観測を「通知」と「初動」につなげます。
アラートは作っただけでは効きません。
誰が何をするかまで決めて初めて、予算超過を未然に止められます。
しきい値の決め方(段階通知で早めに気づく)
しきい値は一発勝負にしないほうが運用が安定するので、おすすめは段階通知です。
例えば、月次予算に対して50%、80%、100%のように分け、80%で原因調査を開始し、100%で対策判断に入る流れが作れます。
ポイントは「100%で初めて気づく」を避けることです。
早めに兆しを拾えば、業務影響の少ない対策(実行時間の変更、クエリ修正)で収まりやすくなります。
予算の単位をどう切るか(部門、環境、プロジェクト)
予算単位は、責任が持てる粒度に切りましょう。
全社一括だと「誰の問題か」が曖昧になり、改善が進みません。
現実的には、環境別(開発/検証/本番)、部門別、プロジェクト別のいずれかから始めるのが進めやすいです。
通知先と初動(誰が止血し、誰が原因分析するか)
通知先は「見る人」ではなく「動ける人」にします。
緊急停止の担当と、原因分析(恒久対策)の担当が違うケースも多いので、役割を分けて定義しておくと混乱しません。
例えば、運用担当が停止、データ担当が原因分析、事業責任者が業務影響の判断、といった分担が典型です。
体制が小さい場合は、止血と分析を同一担当にし、判断ラインだけ明確にしておくと回ります。
検知から対応までの運用フロー(連絡、判断、記録)
アラートを受けたら「誰に連絡し」「何を確認し」「どこまで許容し」「どこで止めるか」を決めましょう。
ここが曖昧だと、アラートが増えるほど現場が疲弊します。
運用フローは、チェックリスト形式にして、記録(いつ、何が原因で、何をしたか)を残すと再発防止に効きます。
経営側への説明も、記録があるだけでスムーズになります。
こんにちは、DX攻略部のkanoです。 Snowflakeで分析を始めると、最初にぶつかるのがクエリ(SQLで書く命令文)の基本と、実行環境(ウェアハウス)の扱いです。 この記事では、クエリの書き方だけでなく、速さとコストに直結[…]

Snowflakeならではのメリット(予算超過を制御しやすい理由)
この章では、Snowflakeで予算超過を抑えやすい理由を整理します。
「緊急停止できる」「再発を防げる」設計があると、利用拡大の意思決定もしやすくなります。
ストレージとコンピュート分離で調整しやすい
Snowflakeは、計算処理(コンピュート)と保管(ストレージ)を分けて考えやすい設計です。
予算超過の多くはコンピュート側なので、原因と対策をコンピュート中心に寄せられます。
調整の焦点がはっきりすることで、対策の優先順位も付けやすくなります。
ウェアハウス単位で負荷とコストを分離できる
ウェアハウスを用途別に分けると、業務ごとにコストを見られます。
結果として「誰が何に使ったか」を説明しやすくなり、無理なコスト削減ではなく、納得感のある最適化が進みます。
部門別のショーバック(可視化)やチャージバック(費用配賦)を進める土台にもなります。
自動中断と自動再開でムダ稼働を減らせる
AUTO_SUSPEND(自動中断)とAUTO_RESUME(自動再開)は、ムダ稼働の削減に直結します。
特に開発・検証では効果が大きく、「気づいたら回り続けていた」を減らせます。
まずはここを徹底すると、予算超過の発生頻度が目に見えて下がるはずです。
ガードレールを設定に落とし込みやすい
Snowflakeには、リソースモニター(クレジット使用を監視し、通知や停止を行える機能)があります。
予算超過の事前検知と止血を、設定として組み込める点が大きな強みです。
運用ルールを口約束にせず、仕組みで守れる状態にすると、利用拡大と統制を両立しやすくなります。
こんにちは、DX攻略部のkanoです。 経営のスピードが市場の勝敗を分ける中、「意思決定に必要な数字が出てくるまで数日〜数週間かかる」という声は今も少なくありません。 現場からExcelが集まってくるのを待ち、情報システム部門に[…]

すぐ効く停止策(当日〜1週間でやること)
この章では、予算超過が起きそうなときに「まずやるべきこと」をまとめます。
短期間で効く対策に絞ることで、現場の負担を増やしすぎずにリスクを下げられます。
自動中断の徹底(学習、検証、夜間バッチの基本設定)
最優先は自動中断の徹底です。
開発・検証のウェアハウスは、短い自動中断でも業務影響が出にくく、効果が出やすい領域です。
加えて、夜間バッチのウェアハウスは「処理が終わったら止まる」前提にしておくと、停止忘れが発生しにくくなります。
ここを整えるだけで、ムダな固定費が減ります。
ウェアハウスサイズとスケール設定の見直し
ウェアハウスのサイズが過大だと、同じ処理でもコストが膨らみます。
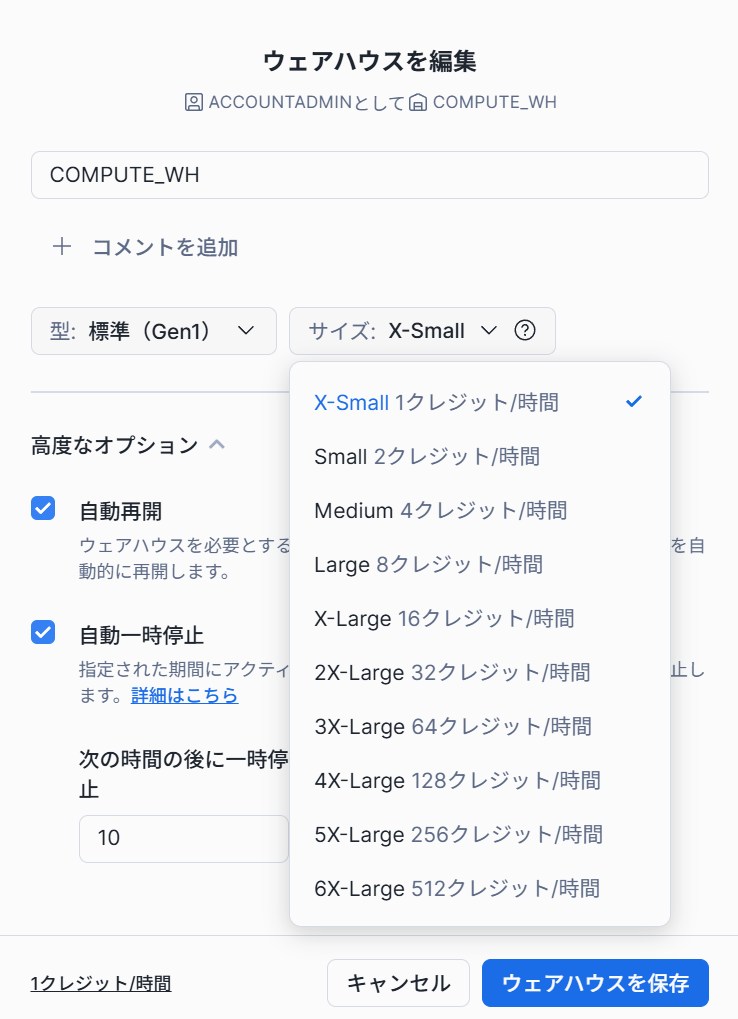
まずは「本当にそのサイズが必要か」を確認しましょう。
また、マルチクラスターの設定は便利ですが、同時実行が増えるほどコストが上がりやすい面もあります。
並列性が本当に必要な業務だけに限定し、他は用途別に分けるほうが管理しやすくなります。
高コストクエリの応急対応(対象範囲の制限、実行タイミング調整)
高コストクエリは、恒久対応の前に応急対応が効きます。
対象期間を絞る、列を減らす、実行頻度を下げる、ピーク時間を避けるだけでも、当月の予算超過を避けられることがあります。
ここで重要なのは「停止を優先し、原因分析は後追いでもよい」と割り切ることです。
コスト要因の可視化(タグ付け、命名規則、実行主体の特定)
停止策と並行して、原因が追える状態を作ります。
ウェアハウスの命名規則、タグ付け(部門や環境の識別)、クエリタグの導入など、軽い仕組みから始めるのがおすすめです。
「誰がどこで何を動かしたか」が追えるだけで、次の対策が速くなります。
こんにちは、DX攻略部のkanoです。 企業のDX推進において、データ活用は欠かせないテーマとなっています。 大量のデータを効率よく保存し、分析や意思決定に役立てるために、多くの企業が「データウェアハウス」を導入しています。 […]

再発防止の運用設計(1か月〜で固めること)
この章では、停止策の次に必要な「仕組み化」を扱います。
ここまで作ると、予算超過が起きても早期に気づける運用になり、説明責任も果たしやすくなります。
環境分離(開発、検証、本番)と権限設計
再発防止の基本は環境分離です。
開発・検証に強めの上限を置き、本番は業務影響を考慮しながら統制します。
同時に、権限設計も重要です。例えば、誰でも自由にウェアハウスを作れる状態だと、予算超過の芽が増えます。
作成や変更は限定し、利用はロールでコントロールする設計に寄せると安定します。
部門別配賦に向けた設計(コストセンターの考え方)
予算超過を「事故」から「管理」へ変えるには、部門別の可視化が効きます。
コストセンター(費用の責任単位)を決め、タグやクエリタグで帰属できるようにしておくと、ショーバックやチャージバックが進めやすくなります。
これにより「削る」ではなく「使うなら根拠をそろえる」運用に変わり、意思決定が早くなります。
定例レビュー(週次、月次)でのチェック項目
運用を回すなら、定例レビューを用意しましょう。
週次では異常増加の有無、月次では予算の振り返りと改善施策の効果を見ます。
チェック項目は、ウェアハウス別の推移、上位高コストクエリ、アラート発生件数、対処の履歴あたりから始めると回しやすいです。
変更管理(新規ツール導入、ジョブ追加時のルール)
再発は「変更」から起きます。
新規ツール、ジョブ追加、頻度変更、データ量増加があったら、予算超過の事前検知に反映させるルールを作りましょう。
具体的には、導入時に「どのウェアハウスで動かすか」「上限とアラート」「責任者」をセットで決める運用にします。
これだけで、予算が読めない状態を減らせます。
こんにちは、DX攻略部のkanoです。 Snowflakeを導入した企業から「経営ダッシュボードをSnowflakeの上に作り直したら、経営会議の中身が変わった」という声が増えてきています。 売上や利益といった結果の数字だけでな[…]

よくあるつまずきと対策
この章では、事前検知と運用がうまくいかない典型パターンを先回りで潰します。
設計の工夫で回避できるものが多いです。
アラートが多すぎて形骸化する
アラートが多すぎると、人は見なくなります。
以下のような対策を実施しましょう。
- 監視対象を絞る
- 段階通知にする
- 初動が必要なものだけ通知する
この3つの対策です。
まずは主要ウェアハウスだけを対象にし、運用が回ってから範囲を広げるほうが成功率が上がります。
しきい値が合わず、誤検知か見逃しになる
しきい値は固定値より、過去平均との差分や増加率で見ると改善しやすいです。
月初は低く、月末は高くなるなど、月内の波も考慮しましょう。
最初は仮のしきい値で始め、1〜2か月で実績を見ながら調整すると現実的です。
止める権限がなく初動が遅れる
事前検知ができても、止められなければ事故は防げません。
停止担当に必要な権限を付与するか、緊急時の連絡・判断フローを明文化しておきましょう。
「誰が止めるか」が決まるだけで、対応時間が短くなります。
原因分析が属人化して対応が続かない
属人化は、記録不足と仕組み不足から起きます。
対策は、対処のテンプレ(確認順、連絡先、判断基準)を作り、対応ログを残すことです。
分析も、まずは上位数本の高コスト要因を潰す運用に寄せると、続けやすくなります。
こんにちは、DX攻略部のkanoです。 サブスクビジネスでは、顧客解約率(一定期間に離脱した顧客の割合)が数ポイント動くだけで、利益と成長スピードが大きく変わります。 一方で「解約の理由が分からない」「分析はしているのに現場が動[…]

相談するなら押さえたい論点
この章では、社内だけで抱え込まずに相談する場合に「何を論点にすべきか」「何を成果物として持ち帰るべきか」を整理します。
予算超過は個社事情が大きいので、論点が揃うと解決が速くなります。
現状診断で確認するポイント(データ、体制、運用、権限)
現状診断では、ウェアハウス構成、利用のピーク、主要ジョブ、直近の急増ポイントを確認します。
加えて、誰が停止するか、誰が原因分析するか、どこまで止めてよいか、といった体制と権限も重要です。
この4点が揃うと、対策が「設定の話」だけで終わらず、運用として定着します。
PoCで作る成果物(アラート設計、運用フロー、再発防止チェックリスト)
PoC(概念実証)で作る成果物は、アラートのしきい値設計、通知先と初動フロー、定例レビューのチェック項目、変更管理のルールまでを一式にすると効果的です。
これにより、予算超過を「都度対応」から「仕組みで防ぐ」に切り替えられます。
よくある質問(FAQ)
この章では、現場でよく出る疑問に短く答えます。読者が次の一手を決めやすいように整理します。
予算超過が起きたとき、最初に見るべきものは何ですか
まずはウェアハウス別の利用推移を見て、急増しているウェアハウスを特定しましょう。
次に、そのウェアハウスのクエリ履歴で高コスト要因を上位から確認し、実行主体(ユーザー/ロール)まで降りると、停止と連絡がスムーズです。
いきなり全体を見直すより、火元を絞るほうが短時間で収まります。
監視はどの頻度で回すのが現実的ですか
最初は日次で十分です。
日次で兆しが拾えるようになったら、急増しやすい業務だけ時間帯監視を追加すると無理がありません。
運用が回らない頻度にすると形骸化するため、続く頻度から始めて改善しましょう。
本番に影響を出さずに事前検知するコツはありますか
段階通知を基本にし、いきなり停止にしないことがコツです。
80%で原因調査、100%で停止判断のように、業務影響をコントロールできる設計にします。
あわせて、用途別のウェアハウス分離と、開発・検証に強めのガードレールを置くと、本番を守りながら改善を進めやすくなります。
こんにちは、DX攻略部のkanoです。 データ活用やDXの文脈で「ダッシュボードを作りたい」「Snowflakeで可視化したい」という相談はとても増えていますが、そもそもSnowflakeのダッシュボードがどのようなものなのか、イメー[…]

まとめ
Snowflakeの予算超過を事前検知する方法について解説しました。
Snowflakeの予算超過を事前検知するには、まず「どのウェアハウスが増えたか」を軸に兆しを拾い、クエリと実行主体へ切り分ける流れを固定しましょう。
そのうえで、段階通知のアラート設計と、停止・原因分析の役割分担を運用に落とし込むと、事故が減りやすくなります。
当日〜1週間は自動中断の徹底と高コスト要因の止血が効きます。
1か月〜は環境分離、権限設計、部門別配賦、変更管理までを整え、再発防止を仕組み化しましょう。
予算を守ることは利用を止めることではなく、「安心して使い続けるための統制」を作ることです。
Snowflakeの導入を検討している方は、DX攻略部で紹介している、その他のSnowflakeの記事も参考にしていただければと思います。
そして、DX攻略部では、Snowflake×Streamlitを活用した統合BI基盤構築支援サービスを行っていますので、Snowflake導入を検討している企業様はぜひDX攻略部にご相談ください!





