
こんにちは、DX攻略部のkanoです。
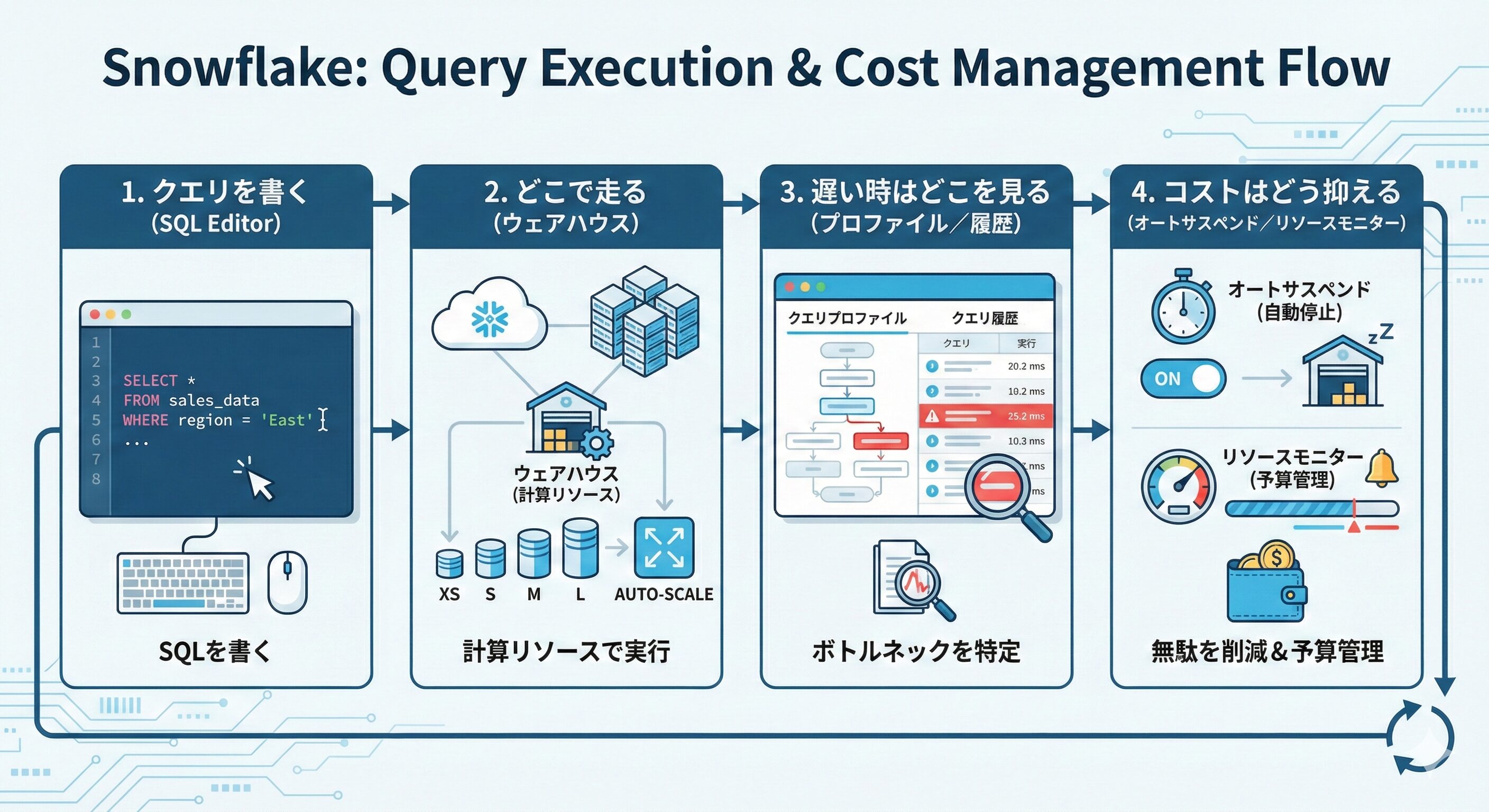
Snowflakeで分析を始めると、最初にぶつかるのがクエリ(SQLで書く命令文)の基本と、実行環境(ウェアハウス)の扱いです。
この記事では、クエリの書き方だけでなく、速さとコストに直結する実行環境、動かない時の確認ポイントまでをまとめて整理します。
読み終えるころには『どこで実行して、どこを見て改善するか』が分かる状態を目指しましょう。
そして、DX攻略部では、Snowflake×Streamlitを活用した統合BI基盤構築支援サービスを行っています。
記事の内容を確認して、Snowflakeを自社に活用してみたいと考えた方は、下記のボタンをクリックしてぜひDX攻略部にご相談ください!
クエリとは?Snowflakeでの基本概念
ここでは、クエリの基本とSnowflake特有の考え方をつかみます。
まずは全体像をイメージし、そのうえでSQLのどこが共通でどこがSnowflake流かを押さえます。
クエリとは?
クエリは「コンピューターに対する質問や指示」です。
データベースの世界では、欲しいデータややりたい処理をSQLという言語で書いた命令文を指します。
そのため、以下のようなことをクエリは実行します。
-
読む:必要なデータを取り出す(SELECT)
-
書く:データを追加・更新・削除する(INSERT/UPDATE/DELETE/MERGE)
-
定義・管理:テーブルを作る・変更する(CREATE/ALTER/DROP)※これらも広い意味ではクエリ(SQL文)に含まれます
クエリを使って、「商品別に売上件数を集計して、上位10件を見せて」という指示を出したい場合は、SQLだと次のように表現します。
SELECT item, COUNT(*) AS cnt
FROM sales
WHERE order_date >= '2025-01-01'
GROUP BY item
ORDER BY cnt DESC
LIMIT 10;Snowflakeでは、上のようなSQL文を仮想ウェアハウス(計算リソース)で実行します。
実行前に「どのロール・どのウェアハウス・どのスキーマを使うか」という実行コンテキストを決める形です。
ワークシートのエディターでSQLを実行→結果を確認→必要ならクエリ履歴やクエリプロファイルで内容と性能を振り返る、という流れになります。
つまりクエリとは、「欲しいデータ」や「行いたい処理」を機械に正確に伝えるための文(命令)であり、Snowflakeではその文をSQLで書いて実行するとイメージしてください。
SQLとSnowflakeクエリの関係
Snowflakeは標準SQLを広くサポートし、JOINやウィンドウ関数、サブクエリなど一般的な構文が使えます。
加えてQUALIFYなどの拡張があり、同じ結果をより簡潔に書ける場面があります。
ストレージと計算の分離が意味すること
データはクラウドストレージに保存され、クエリは仮想ウェアハウスで実行されます。
複数チームが同じデータを同時に使えて、計算リソースは用途に応じて独立して増減できます。
メタデータとキャッシュの基本
実行時は統計情報をもとに最適化され、結果キャッシュやウェアハウスキャッシュの効果で再実行が速くなることがあります。
更新頻度や実行パターンを揃えると安定した性能が得られます。
Snowflakeならではのメリット
Snowflakeのクエリ運用がやりやすい理由は、ストレージ(データの保管場所)と計算(クエリを動かす力)が分かれている点にあります。
必要な時だけウェアハウス(計算リソース)を動かし、不要な時は止められるため、コストと性能を両立しやすくなります。
さらにキャッシュやメタデータ(データの説明情報)を活用できるので、同じ分析を繰り返す業務ほど効率が出やすいのも特徴です。
こんにちは、DX攻略部のkanoです。 「Snowflakeについて調べていると、ウェアハウスという言葉がよく出てくるけど、これってなに?」 「ウェアハウスの仕組みや使う上でのポイントを知りたい」 Snowflakeの「ウ[…]

実行環境の基礎:仮想ウェアハウスとクエリの関係
ここではクエリがどこで動くのか、速度やコストに直結する実行環境の考え方を確認します。
最初は小さく始め、必要に応じて段階的に調整するのが安全という点も覚えておきましょう。
クエリで勘違いしやすい点
クエリはデータベースそのものではなく、仮想ウェアハウスという計算リソースに紐づいて実行されます。
ウェアハウスはクエリが到着すると起動し、クラウド上のストレージにあるデータを読み取り、処理が終わると停止できます。
つまり、クエリの速度はウェアハウスの性能と混雑度に、コストはウェアハウスが動いている時間と台数に強く連動します。
最初は小さく始め、待ち行列や処理時間を見ながら段階的に調整するのが安全です。
クエリはどこで走るのか
クエリ1本は必ず1つのウェアハウスで実行されます。
ウェアハウスはCPUやメモリを束ねた計算クラスターで、クエリはここでスキャン・結合・集計などの演算を行います。
データは別の層(ストレージ)にあり、必要な範囲だけを読み込みます。
その中で速度に効くのはサイズか台数か、という疑問が出てくるかもしれません。
-
サイズを上げる(縦に大きく)
1本あたりのクエリが重い時に効果的です。演算資源が増え、単発の処理時間短縮が見込めます。 -
台数を増やす(横に増やす=マルチクラスター)
同時実行が多くてキューが発生する時に有効です。並列で複数のクエリを捌けるため、待ち行列の短縮に効きます。
速度に効くのは、上記のように状況によって適切に選択することが重要です。
データの種類などをもとに検討してみましょう。
オートサスペンド・オートリジュームの基本
アイドル時は自動で一時停止(オートサスペンド)、クエリ到着時に自動再開(オートリジューム)させると、待ち時間を最小にしつつ無駄な稼働を減らせます。
停止までの待機時間は短めに設定し、深夜帯などの無人時間を自動で節約します。
リソースモニターでコストを見える化
月次や部門ごとのクレジット上限を設定し、閾値で通知・停止をかけると、想定外のコスト増を早期に抑制できます。
モニターは用途別(プロジェクト・部門別)に分けると、原因の切り分けが容易です。
こんにちは、DX攻略部のkanoです。 「Snowflakeについて調べていると、ウェアハウスという言葉がよく出てくるけど、これってなに?」 「ウェアハウスの仕組みや使う上でのポイントを知りたい」 Snowflakeの「ウ[…]
Snowflakeクエリの書き方の基本
ここでは日本語UIでの実行手順と、最初に身につけたい書き方の要点を扱います。
ワークシートで小さく試し、良い書き方を体に覚えさせましょう。
日本語UIでの実行手順
サインイン→左ナビでプロジェクト→ワークスペースを開きます。
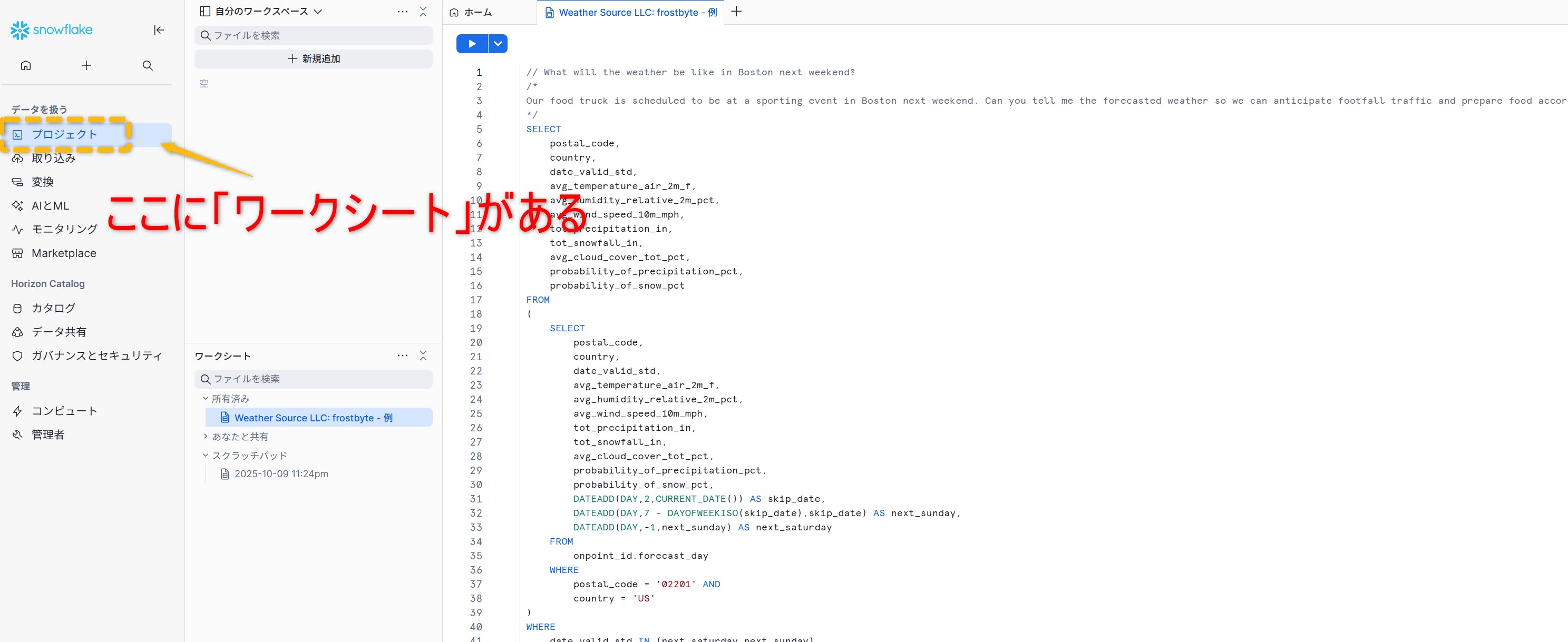
画面上部のコンテキストバーでロール、ウェアハウス、データベース、スキーマを選び、エディターにSQLを入力して実行しましょう。
複数文を扱う場合は、実行したい文だけを選択して走らせると誤実行を防げます。
SELECT・WHERE・GROUP BY・ORDER BYの要点
必要な列だけSELECTし、WHEREで早めに絞り、GROUP BYで集計、ORDER BYで並べ替えます。
この4つは「どの列を出すか→どの行を対象にするか→どうまとめるか→どう並べるか」という役割分担です。
実務では絞る→まとめる→見せ方を決めるの順に考えると迷いません。
-
SELECT=出したい列を決める
-
WHERE=対象の行を先に減らす
-
GROUP BY=グループごとに集計する
-
ORDER BY=最後に表示順を整える
実行される順序は以下の順番です。
※WHEREは行に対する条件、HAVINGは集計後のグループに対する条件
そして以下のような形で活用することが多いです。
-- 必要列だけ取り、先に期間で絞ってから並べる
SELECT order_id, order_date, total_amount
FROM sales
WHERE order_date >= '2025-01-01'
ORDER BY order_date DESC
LIMIT 10;SELECTは学習時は手軽ですが、本番では不要な列まで読み込みI/Oが増えます。
そのため、先にWHEREで対象を減らすほど、その後の並べ替えや集計が軽くなります
集計の定番パターンとして、要件「商品ごとに売上金額を集計し、多い順に上位10件」とする場合なら、以下のように設定してみてください。
SELECT item_name,
SUM(amount) AS total_amount
FROM sales
WHERE order_date BETWEEN '2025-01-01' AND '2025-01-31'
GROUP BY item_name
ORDER BY total_amount DESC
LIMIT 10;GROUP BYに含めない列は集計関数で包む(SUMやCOUNTなど)ことや、並べ替えの対象は集計後の列名(ここではtotal_amount)するのがポイントです。
スキーマ修飾と完全修飾名
スキーマ修飾は、テーブルやビューなどのオブジェクト名の前にスキーマ名を付けて書くことです。
完全修飾名は、データベース、スキーマ、オブジェクト名で書く指定方法です。
開発・検証・本番など複数の環境に同名テーブルがある場合でも、参照先を間違えずに済みます。
-
参照先の誤りを防止する
-
実行環境(開発/本番)が変わっても同じクエリで正しく動かす
-
レビュー時に参照先が一目でわかるようにする
Snowflakeは指定が省略されると現在のデータベースとスキーマ(コンテキスト)を使いますが、意図しない場所を参照して不具合や事故につながりやすいため、重要な処理ほど完全修飾名を使うのが安全です。
代表的な書き方の例は以下のようになります。
-- テーブル/ビュー
SELECT *
FROM SALES.RAW.ORDERS;
-- 関数呼び出し(スキーマ修飾)
SELECT UTIL.PUBLIC.FISCAL_WEEK(order_date) AS fiscal_week
FROM SALES.MARTS.DAILY_SALES;
-- DML/DDLでも同様
CREATE TABLE ANALYTICS.STAGE.NEW_ORDERS AS
SELECT * FROM SALES.RAW.ORDERS;「object does not exist エラー」と表示された場合は、コンテキストが違うか、スペル/大文字小文字が不一致です。
完全修飾名で再実行し、CURRENT_DATABASE/SCHEMA を確認しましょう。
こんにちは、DX攻略部のkanoです。 「SnowflakeのSnowparkで何ができるの?」 こういった疑問をお持ちではありませんか? Snowparkは、Snowflakeの中でPythonなどのコードを動かし、デー[…]

権限とオブジェクト:動かない時の確認ポイント
Snowflakeのクエリを使った際に、うまく動かない場合はどういったことが考えられるのでしょうか。
Snowflakeのクエリ関係でエラーが起きるのを防ぐために、権限とオブジェクトについて学んでおきましょう。
クエリが失敗する原因は権限や指示のミス
クエリが失敗する原因の多くは、実はSQLの文法ではなく「誰として実行しているか(ロール)」「どこにある何を触ろうとしているか(完全修飾名で指し示せているか)」「どの計算資源で動かしているか(ウェアハウス)」の三点にあります。
ここを順番に確認できれば、ほとんどの動かないを数分で解決できます。
ロールと権限の考え方
SnowflakeはRBAC(ロールベースアクセス制御:役割に権限を付与する仕組み)が基本です。
ユーザーに権限を直接付けるのではなく、ロールに権限を付け、ユーザーは作業内容に応じてロールを切り替えて行動します。
最小権限(必要最小限だけ付与する考え方)で、閲覧用、開発用、管理用を分けると運用が安定します。
GRANT USAGE ON WAREHOUSE BI_WH TO ROLE ANALYST;
GRANT USAGE ON DATABASE SALES TO ROLE ANALYST;
GRANT USAGE ON SCHEMA SALES.MARTS TO ROLE ANALYST;
GRANT SELECT ON ALL TABLES IN SCHEMA SALES.MARTS TO ROLE ANALYST;
-- 以降に作られるテーブルにも自動付与したい場合
GRANT SELECT ON FUTURE TABLES IN SCHEMA SALES.MARTS TO ROLE ANALYST;また、上記のように運用設計では「閲覧用」「開発用」「管理用」のようにロールを分け、最小権限で付与するのが基本です。
USEで実行コンテキストを固定する
ワークシート上部で切り替えるだけでなく、冒頭にUSE ROLE、USE WAREHOUSE、USE SCHEMAを明記して実行環境を固定すると誤実行を防げます。
USE ROLE ANALYST;
USE WAREHOUSE BI_WH;
USE DATABASE SALES;
USE SCHEMA MARTS;よくあるアクセスエラー
Snowflakeクエリにおいて、エラーが起きることがあります。
見つからない、権限が不足している、というエラーはスキーマ違いか権限不足のサインです。
完全修飾名と権限付与の両面から確認します。
こんにちは、DX攻略部のkanoです。 「Snowflakeをもっと便利に活用したい」と思ったことはありませんか? Snowflakeを使い始めると、「データを取り込む作業」そのものが意外とボトルネックになります。 特にロ[…]

よく使うSQLとSnowflake拡張
標準SQLに加えてSnowflake独自の便利機能を押さえると、短く読みやすく、速いクエリに近づきます。
ウィンドウ関数と近似集計
ウィンドウ関数は「行を残したまま集計や順位付けを付与」できる道具です。
集計結果を別テーブルにしなくても、同じ行の横に累計や順位の列を追加できます。
累計の付与を行う場合は、以下のように設定します。
SELECT customer_id,
order_date,
amount,
SUM(amount) OVER (
PARTITION BY customer_id
ORDER BY order_date
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
) AS running_amount
FROM sales;順位付けと同着対応では、以下のように設定しましょう。
SELECT item_id, sales_amount,
RANK() OVER (PARTITION BY category ORDER BY sales_amount DESC) AS rnk,
DENSE_RANK() OVER (PARTITION BY category ORDER BY sales_amount DESC) AS dense_rnk
FROM daily_item_sales;RANKは同着の次の順位が飛び、DENSE_RANKは飛びません。
明細単位で最新行だけを残す用途ならROW_NUMBERが定番です。
QUALIFYでネストを減らす
QUALIFYは「ウィンドウ関数の結果を直接フィルタ」できるSnowflake拡張です。
副問い合わせを作らずに最終行だけを残すなどの典型パターンが短く書けます。
最新行だけを取る場合は、以下のように設定します。
SELECT id, updated_at, value
FROM t
QUALIFY ROW_NUMBER() OVER (
PARTITION BY id
ORDER BY updated_at DESC
) = 1;上位◯位をグループごとにフィルタしたい場合は、以下のように設定しましょう。
SELECT category, item, sales_amount
FROM daily_item_sales
QUALIFY ROW_NUMBER() OVER (
PARTITION BY category
ORDER BY sales_amount DESC
) <= 3;サブクエリ版と比べると、QUALIFY版は読みやすく保守が楽です。
各IDの最新行だけを取るときはROW_NUMBERとQUALIFYの組み合わせが定番です。
日時・タイムゾーン関数の基礎
Snowflakeのタイムスタンプは3種類あり、用途で使い分けると事故が減ります。
- TIMESTAMP_NTZはタイムゾーン情報なし。
- TIMESTAMP_LTZはセッションのタイムゾーンで表示されます。
- TIMESTAMP_TZは各値がタイムゾーンを保持します。
よく使う関数は以下のような関数です。
-- 日付単位に切り落とし
SELECT DATE_TRUNC('day', event_ts) AS d, COUNT(*) FROM events GROUP BY d;
-- 期間差の計算
SELECT DATEDIFF('hour', start_ts, end_ts) AS hours;
-- タイムゾーン変換(UTC→東京)
SELECT CONVERT_TIMEZONE('UTC','Asia/Tokyo', event_ts_utc) AS event_jst;
-- 文字列から安全に変換(失敗時NULL)
SELECT TRY_TO_TIMESTAMP_NTZ('2025-10-01 12:34:56') AS ts;実務では「保存時はUTCのTIMESTAMP_NTZ、表示時にタイムゾーン変換」か「TIMESTAMP_LTZでセッションのTIMEZONEを統一」のどちらかに寄せるとわかりやすくなります。
日付キーで集計する時はDATE_TRUNCで粒度を揃えてからGROUP BYするのがポイントです。
ビジネス上の基準タイムゾーンを決めておくと不整合を防げます。
文字列・正規表現・配列の小技
レポート作成前のちょっとした整形もSQLで済ませられます。
-- 大文字小文字を無視した部分一致
SELECT * FROM customers WHERE email ILIKE '%@example.com';
-- 区切り文字で分割しN番目を取得(1始まり)
SELECT SPLIT_PART(full_name,' ',1) AS first_name FROM users;
-- 正規表現で抽出
SELECT REGEXP_SUBSTR(url, 'https?://([^/]+)') AS host FROM access_logs;
-- 配列要素を取り出す(セミ構造化と併用しやすい)
SELECT ARRAY_SIZE(tags) AS tag_count FROM articles;このように標準SQLに加えてSnowflake独自の便利機能をどんどん活用していきましょう。
ビューとマテリアライズドビューの使い分け
再利用性、応答速度、更新コストの三点で選びます。
まずはビューで柔軟に設計し、アクセス集中する集計はマテリアライズドビューで高速提供に切り替えるのが実務的です。
クエリにおけるビューとマテリアライズドビューの関連
クエリは最終的に「何に対して実行するか」で速度もコストも保守性も大きく変わります。
実務ではテーブルだけでなく、ビューやマテリアライズドビューを対象にクエリを書く場面が頻出です。
つまり、クエリの良し悪しを左右する土台がビュー系オブジェクトであり、これを理解していないと正しい設計判断ができません。
ビューは「計算の設計図」、マテリアライズドビューは「前計算して結果を持つ設計図」です。
どちらに対してSELECTするかで、同じSQLでも体感時間やスキャン量が変わります。
リフレッシュの仕組みと制約
マテリアライズドビューは内部に結果を保持し、差分更新されます。
依存関係が多すぎると再計算が重くなるため、設計段階で適度に分割することを心がけましょう。
同様に重いJOINや集計を毎回クエリ内で実行すると時間もクレジットも消費します。
定義が固まった集計はマテリアライズドビュー化すれば、実行時の計算を減らせます。
逆に探索段階ではビューに留めて柔軟性を確保します。これはクエリ最適化の実務的な第一手です。
ガバナンスとセキュリティの担保
内部構造の露出を防ぎたいときはセキュアビューを使います。
列マスキングや行アクセスポリシーと組み合わせると安全に公開できます。
このようにセキュアビューやマスキングポリシー、行アクセスポリシーと組み合わせると、利用者や用途に応じて見せてよいデータだけを安全に返せます。
クエリを書き換えずに安全性を保てるため、運用コストを下げられます。
その他では、ビジネスロジックをビューに閉じ込めれば、アプリ側やダッシュボード側のクエリは短く読みやすくなるのもポイントです。
変更はビュー定義を更新するだけで一斉に反映でき、レビューやテストも楽になります。
こんにちは、DX攻略部のkanoです。 顧客データを活用したマーケティングは「つなぐ力」で成果が大きく変わります。 Snowflakeはデータのサイロを解消し、分析と配信の両方に耐える柔軟な基盤を提供するツールです。 顧客デー[…]

それぞれの使い分けのイメージ
では、そのまま書くパターンとビューでロジックを再利用するパターンとマテリアライズドビューで高速応答するパターンを紹介します。
そのまま各パターンでは、以下のようになります。
-- 重いJOINと集計を毎回実行
SELECT d, item_id, SUM(amount) AS total_amount
FROM (
SELECT DATE_TRUNC('day', o.order_ts) AS d, o.item_id, o.amount
FROM SALES.RAW.ORDERS o
JOIN SALES.DIM.ITEMS i ON o.item_id=i.item_id
WHERE o.status='COMPLETED'
) t
GROUP BY 1,2;ビューでロジックを再利用する場合は以下の形です。
CREATE OR REPLACE VIEW SALES.MARTS.V_ORDERS_CLEAN AS
SELECT DATE_TRUNC('day', o.order_ts) AS d, o.item_id, o.amount
FROM SALES.RAW.ORDERS o
JOIN SALES.DIM.ITEMS i ON o.item_id=i.item_id
WHERE o.status='COMPLETED';
-- 以降のクエリは短くなる
SELECT d, item_id, SUM(amount) AS total_amount
FROM SALES.MARTS.V_ORDERS_CLEAN
GROUP BY 1,2;そして、マテリアライズドビューで高速応答させる場合は以下のようにしましょう。
CREATE OR REPLACE MATERIALIZED VIEW SALES.MARTS.MV_SALES_DAILY AS
SELECT DATE_TRUNC('day', o.order_ts) AS d, o.item_id, SUM(o.amount) AS total_amount
FROM SALES.RAW.ORDERS o
JOIN SALES.DIM.ITEMS i ON o.item_id=i.item_id
WHERE o.status='COMPLETED'
GROUP BY 1,2;
-- ダッシュボードは即時表示に近づく
SELECT * FROM SALES.MARTS.MV_SALES_DAILY
WHERE d >= '2025-10-01'
ORDER BY d DESC;このように、同じ「欲しい結果」を得るにも、どの土台に向けてクエリを書くかで体験が変わります。
データ保護とガバナンスに関わるクエリ
Snowflakeの運用では、「誰が、どのデータを、どこまで見られるか」をクエリ実行前に設計し、運用で迷わない型を作ることが重要です。
最小権限の原則を守りつつ、行レベルの見せ分けや列のマスキング、外部への安全な共有までをクエリ視点で押さえます。
先に土台を正しく整えるほど、アプリやダッシュボード側のクエリはシンプルで安全になります。
行レベルアクセス制御
ユーザーの属性やロールに応じて、同じテーブルから見える行を切り替えます。
-- 地域ごとに閲覧行を切り替える行アクセス制御ポリシー
CREATE OR REPLACE ROW ACCESS POLICY SALES.SECURITY.RA_REGION AS (region STRING)
RETURNS BOOLEAN ->
CASE
WHEN CURRENT_ROLE() IN ('APAC_ANALYST') THEN region = 'APAC'
WHEN CURRENT_ROLE() IN ('EMEA_ANALYST') THEN region = 'EMEA'
ELSE FALSE
END;
-- テーブルのregion列に対して適用
ALTER TABLE SALES.MARTS.ORDERS
ADD ROW ACCESS POLICY SALES.SECURITY.RA_REGION ON (region);1つのテーブルを保ちつつ、部門や地域で閲覧範囲を分けたい時に有効です。
マスキングポリシーとタグ
列単位で値を伏せ字や派生値に置き換えます。
-- メールアドレスをロールに応じてマスク
CREATE OR REPLACE MASKING POLICY SALES.SECURITY.MP_EMAIL AS (val STRING)
RETURNS STRING ->
CASE
WHEN CURRENT_ROLE() IN ('PII_VIEWER') THEN val
ELSE CONCAT('***@', SPLIT_PART(val,'@',2))
END;
-- 列に適用
ALTER TABLE SALES.MARTS.CUSTOMERS
ALTER COLUMN email SET MASKING POLICY SALES.SECURITY.MP_EMAIL;メールや電話番号、個人識別子などの安全な公開に必須です。
セキュアビューの基礎
セキュアビューは内部構造を露出させずに公開するためのビューです。
CREATE OR REPLACE SECURE VIEW SALES.SHARED.V_ORDERS_PUBLIC AS
SELECT order_id,
TO_CHAR(order_ts,'YYYY-MM-DD') AS order_date,
email_masked, -- 事前にマスクされた列を参照
total_amount
FROM SALES.MARTS.ORDERS_PUBLIC;高速化の機能ではなく、配布時の安全性と秘匿性を高める仕組みです。
列のマスキングや行アクセス制御と組み合わせて使います。
運用に役立つ機能とクエリ
運用の安定は「定期実行」「履歴の可視化」「万一の復旧」の三本柱で決まります。
ここでは、Snowflake標準の仕組み踏まえながら、どんなSQLを添えると現場が回るかを実務目線で整理します。
タスク・ストリームでの定期実行
ストリームはテーブルの変更差分を捉える仕組み、タスクはSQLや手続きの定期実行スケジューラです。
-- 差分を掴むストリーム
CREATE OR REPLACE STREAM SALES.MARTS.ST_ORDERS
ON TABLE SALES.RAW.ORDERS;
-- 毎時実行する取り込みタスク
CREATE OR REPLACE TASK SALES.MARTS.TK_LOAD_ORDERS
WAREHOUSE = ETL_WH
SCHEDULE = 'USING CRON 0 * * * * Asia/Tokyo'
AS
INSERT INTO SALES.MARTS.ORDERS_DELTA
SELECT * FROM SALES.RAW.ORDERS
WHERE METADATA$ISUPDATE OR METADATA$ACTION = 'INSERT';2つを組み合わせると、軽量な増分処理パイプラインが作れます。
タイムトラベルで履歴にクエリ
タイムトラベルは保持期間内なら過去時点のデータを参照・復元できる仕組みです。
誤削除や誤更新に強く、監査にも役立ちます。
-- 過去時点の内容を参照(時刻で指定)
SELECT * FROM SALES.MARTS.ORDERS
AT (TIMESTAMP => '2025-10-01 00:00:00'::TIMESTAMP_TZ);
-- 指標を過去時点で再集計(差分の原因調査に便利)
SELECT DATE_TRUNC('day', order_ts) d, SUM(amount)
FROM SALES.MARTS.ORDERS
AT (TIMESTAMP => '2025-10-01 00:00:00'::TIMESTAMP_TZ)
GROUP BY 1;
-- 誤ってDROPしたテーブルを復元
UNDROP TABLE SALES.MARTS.ORDERS;
-- 重要テーブルの保持期間を延長(要件に合わせて設定)
ALTER TABLE SALES.MARTS.ORDERS
SET DATA_RETENTION_TIME_IN_DAYS = 7;運用のコツとして、重要テーブルは保持期間を要件に合わせて設定し、コストと復旧力のバランスを取るのがおすすめです。
復元は本番データへの影響が大きい操作なので、まずは一時スキーマへ復元して検証することを忘れないようにしましょう。
エラー調査とQUERY_HISTORY
クエリが遅い、失敗が増えた、という時は、履歴とプロファイルの両輪で原因を特定しましょう。
-- 直近の失敗クエリを一覧
SELECT query_id, user_name, warehouse_name, error_code, error_message, start_time
FROM SNOWFLAKE.ACCOUNT_USAGE.QUERY_HISTORY
WHERE start_time >= DATEADD('hour', -6, CURRENT_TIMESTAMP())
AND error_code IS NOT NULL
ORDER BY start_time DESC;
-- 指定クエリを中断(影響範囲を確認してから実行)
SELECT SYSTEM$CANCEL_QUERY('01b0a1f0-1200-9bcd-0000-000123456789');遅い時はクエリプロファイルで「一番重いノードの入力量」を減らす対策から行い、エラーはエラーメッセージだけでなく、直前に変わったロール・ウェアハウス・オブジェクト変更履歴も合わせて確認してください。
こんにちは、DX攻略部のkanoです。 顧客データを活用したマーケティングは「つなぐ力」で成果が大きく変わります。 Snowflakeはデータのサイロを解消し、分析と配信の両方に耐える柔軟な基盤を提供するツールです。 顧客デー[…]
よくある疑問をまとめて解決(Q&A)
最後にクエリに関する疑問をまとめて解決しましょう。
疑問は素早く解決し、放置しないことが重要です。
なぜ同じクエリでも時間が変わるのか
クエリを使っていると時間の違いを感じることがあるかもしれません、
これはキャッシュの有無、データ量の増減、同時実行による混雑、ウェアハウスのサイズやクラスター数の違いが影響しているのです。
- キャッシュ(前回結果の再利用)の有無
- 対象データ量の増減(期間や条件の違い)
- 同時実行の混雑(キューの発生)
- ウェアハウスのサイズ、マルチクラスターの設定差
迷ったら最初にクエリプロファイルで『どこが一番重いか』を確認し、必要列だけ取得、早めのフィルター適用から着手しましょう。
-- 期間で先に絞る→後段の処理が軽くなる
WITH s AS (
SELECT order_id, customer_id, amount
FROM sales
WHERE order_date >= '2025-10-01'
)
SELECT c.segment, SUM(s.amount)
FROM s
JOIN customers c ON s.customer_id=c.customer_id
GROUP BY c.segment;このように早めにフィルターしてから集計・結合するといった形にするだけでも、処理時間の改善が期待できます。
単発のクエリ自体が重い場合は、サイズを上げ、待ち行列が出て着手が遅い場合は、クラスター数を増やす(マルチクラスター)という対応がおすすめです。
JOINが遅い時の対処は
結合キーの型不一致や欠損を解消し、不要列を落として入出力を削減します。
可能な限り結合前にフィルターを適用し、重い集計は段階的にサマリ化します。
小さなウェアハウスでも速くするには
ウェアハウスは、小さく始めて必要列だけ取得、再利用する分析はビューやマテリアライズドビュー化します。
詰まりが見えたらマルチクラスターを検討します。

Snowflakeのコストを抑える上で適切なウェアハウスの使い方は重要なので、定期的に確認しておきましょう。
コストを抑える実践的なコツ
オートサスペンドを短めに、再実行が多い分析は条件を安定させましょう。
また、夜間バッチは短時間で終わるよう一時的にサイズアップするのも有効です。
こんにちは、DX攻略部のkanoです。 Snowflakeの導入や活用を外部コンサルに頼るべきか、どのように契約し何を成果物として受け取り、どんなKPIで評価すればよいか、初めてだと判断が難しいポイントが多いものです。 本記事で[…]

まとめ
Snowflakeでのクエリ運用は、実行環境を小さく始めて段階的に調整し、良い書き方を身につけ、プロファイルと履歴で検証し続けるのが近道です。
クエリは「コンピューターに対する質問や指示」であることを理解しましょう。
また、クエリの「読む」「書く」「定義」という役割を活用し、Snowflakeより良く扱うことが重要です。
クエリについて学んだら、DX攻略部で紹介している、その他のSnowflakeの記事も参考に、その機能をフル活用しましょう。
そして、DX攻略部では、Snowflake×Streamlitを活用した統合BI基盤構築支援サービスを行っていますので、Snowflake導入を検討している企業様はぜひDX攻略部にご相談ください!









