
こんにちは、DX攻略部のkanoです。
「Snowflakeを導入してみたいけど、専門用語が多くて難しそう」
「Snowflakeを使う上で知っておくべき、基本用語を網羅したい」
Snowflakeは、データ分析やAI活用の土台になるクラウド型のデータ基盤です。
ただ、調べ始めると「ステージ」「ウェアハウス」「動的テーブル」など、聞き慣れない用語が一気に出てきて止まりやすいのも事実でしょう。
本記事では、Snowflakeを触り始めた人が最初に混乱しやすい用語を、役割と使いどころに絞って整理します。
日本語表示のSnowsight(Snowflake標準のUI(ユーザーインターフェース:操作画面))を前提に、「どの画面で何を設定するか」のイメージも持てるようにまとめました。
読み終えたら、まずは小さなデータを取り込み、1つのウェアハウスで実行し、コストと権限を確認するところまで進められます。
そして、DX攻略部では、Snowflake×Streamlitを活用した統合BI基盤構築支援サービスを行っています。
SnowflakeとStreamlitによるデータ可視化ソリューション。業種別ダッシュボードで意思決定を加速。SCD T…
記事の内容を確認して、Snowflakeを自社に活用してみたいと考えた方は、下記のボタンをクリックしてぜひDX攻略部にご相談ください!
Snowflakeの全体像をまず押さえる
Snowflakeは、データをためる領域(ストレージ)と、計算する領域(コンピュート=仮想ウェアハウス)が分かれているのが大きな特徴です。
必要な時だけ計算を起動し、止めれば課金を抑えやすくなります。
この構造を先に押さえると、以降に出てくる「自動サスペンド」「マルチクラスター」「リソースモニター」などのコスト最適化用語が一気につながります。」
最初にSnowflakeの全体像を理解するために必要な用語から確認してきましょう。
仮想ウェアハウス
仮想ウェアハウスはSnowflakeでクエリやデータロードやアンロードを実行するための専用の計算リソースです。
仮想ウェアハウスはストレージと独立しており必要な時だけ起動し不要になれば停止できることを覚えておきましょう。
分析クエリや変換処理や取り込み処理を実行し、1つのクエリは1つの仮想ウェアハウス上で完結します。
ワークロードごとに仮想ウェアハウスを分けることで混雑や干渉を避けられます。
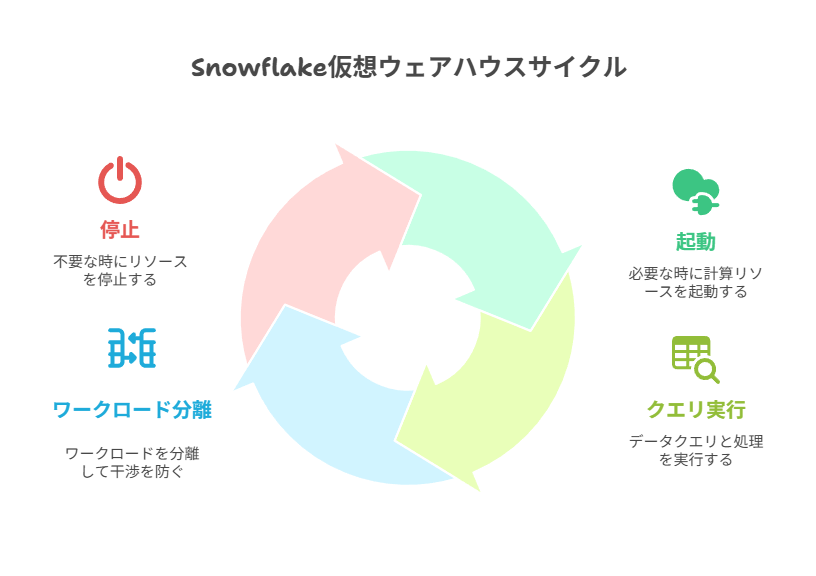
仮想ウェアハウスに関して誤解しがちなのは、仮想ウェアハウスはデータの置き場所ではないという点です。
仮想ウェアハウスのサイズを大きくしても必ずしも速くなるわけではなく、同時実行とSQL設計の影響が大きい点に注意しましょう。
Snowflakeのウェアハウスについては、以下の記事で詳しく解説していますので参考にしてみてください。
こんにちは、DX攻略部のkanoです。 「Snowflakeについて調べていると、ウェアハウスという言葉がよく出てくるけど、これってなに?」 「ウェアハウスの仕組みや使う上でのポイントを知りたい」 Snowflakeの「ウ[…]

クエリ
クエリはSnowflakeに対して「何をどう計算して結果を返すか」を指示するSQL文です。
クエリは仮想ウェアハウス上で実行され、現在のロールやデータベースやスキーマといったコンテキストの影響を受けます。
SELECTのように結果を取得するクエリ、INSERTやUPDATEやDELETEやMERGEなどデータを変更するクエリ、CREATEやALTERやDROPなどオブジェクトを操作するクエリ、COPY INTOのように取り込みや書き出しを行うクエリがあります。
単純な取得の場合に使うクエリの例であれば以下のようになります。
SELECT order_id, amount FROM sales WHERE amount >= 1000;
結合と集計に使うクエリであれば、以下のように設定しましょう。
SELECT c.region, SUM(s.amount) AS total_amount
FROM sales s
JOIN customers c ON s.customer_id = c.customer_id
WHERE s.order_date >= '2025-01-01'
GROUP BY c.region
ORDER BY total_amount DESC;
Snowsight
Snowsightは、Snowflake標準のWeb UI(Web上の操作画面)です。
※本記事に掲載されているSnowflake画面は、サンプル用に用意したアカウントを使用し、Snowflakeサンプルデータを使用したものを掲載しています。
ワークシート(SQLやPythonを実行する画面)、コスト、セキュリティ、ユーザー管理までをまとめて扱えます。
日本語表示に切り替えた画面でも基本の構造は同じなので、日常運用の起点として最初に覚えると迷いにくくなります。
Snowflakeならではのメリット
Snowflakeは、データ基盤の立ち上げを小さく始めやすい設計になっています。
計算(仮想ウェアハウス)を止められるため、検証や学習でもコストを管理しやすい点が現場では効きます。
また、RBAC(ロールベースアクセス制御:役割に権限を付与する仕組み)や監査、列や行の制御が標準機能としてそろっているため、後からセキュリティ設計を付け足す手戻りが減ります。
さらに、データをコピーせずに共有できる仕組み(データシェアやクリーンルーム)も特徴で、社内外の連携が進めやすくなります。
用語を理解することは、機能を知るだけでなく、設計と運用の判断を速くする近道です。
こんにちは、DX攻略部のkanoです。 この記事は、はじめてSnowflakeを触る方が「最初の30分」で迷いやすいポイントだけを先回りして、最低限の動作確認まで進めるためのガイドです。 具体的には、Snowsight(Snow[…]

ステージの基礎(内部と外部とディレクトリテーブル)
ステージは「ファイルの一時置き場」のことです。
内部ステージと外部ステージの違いについて確認しておきましょう。
内部ステージ
内部ステージはSnowflakeアカウント内で完結するステージで、暗号化はSnowflakeが管理します。
アクセス制御はRBAC(ロールベースアクセス制御:役割に権限を付与する仕組み)と連動するため、誰がアップロードできるかをロール設計で管理しやすい点が実務では便利です。
また、設定やアップロードの流れは上記の例のとおりで、検証や小規模な定期取り込みの入り口として使いやすい構成になります。
主な種類は次のとおりです。
-
ユーザーステージ:
@~個人作業用の一時領域 -
テーブルステージ:
@%テーブル名そのテーブル専用の領域 -
名前付きステージ:
@ステージ名DB/スキーマ配下で共有しやすい汎用領域
内部ステージは、開発検証や小規模な定期取り込み、権限や鍵管理をシンプルに保ちたい場合に適しています。
-- 名前付き内部ステージ
CREATE STAGE my_int_stage
FILE_FORMAT=(TYPE=CSV FIELD_OPTIONALLY_ENCLOSED_BY='"' SKIP_HEADER=1);
-- アップロード例(SnowSQL)
PUT file://./data/*.csv @my_int_stage AUTO_COMPRESS=TRUE;上記の様な形で設定できます。
外部ステージ
外部ステージはS3(AWSのクラウドストレージ)やGCS(Googleのクラウドストレージ)やAzure Blob(Microsoftのクラウドストレージ)など、既存の保管場所をSnowflakeから参照する仕組みです。
認証はストレージ統合(STORAGE INTEGRATION)を使うのが推奨で、鍵情報をSQLに直書きせずに運用できます。
外部ステージは大容量データやデータレイク連携で特に効くため、取り込み方式(COPYやSnowpipe)とセットで設計すると失敗しにくくなります。
こんにちは、DX攻略部のkanoです。 「Snowflakeを導入するか悩んでいる」、「実際の操作画面を触りながら使いこなせるか試したい」、「Snowflakeを導入したけど基本や応用を学びたい」 こうした状況で役立つのが、Sn[…]

データ取り込みの用語
Snowflakeのデータ取り込みは、大きくCOPY(まとめて取り込む)と、Snowpipe/SnowpipeStreaming(到着次第取り込む)に分かれます。
どれを選ぶかで、コストの出方(ウェアハウス課金かサーバーレス課金か)と、運用の手間(手動か自動か)が変わります。
先に判断軸を持っておくと、用語がただの暗記になりません。
ここでは各方式の用語と役割、設計ポイント、よくある落とし穴まで整理します。
COPY
COPYはステージ上のファイルをテーブルへ一括で取り込む基本手段です。
検証モードやエラー時の挙動制御、ファイル選択の柔軟さなど、運用に必要な機能が揃っています。
代表的な指定項目として、ファイルフォーマット、対象ファイルの絞り込み(PATTERNやファイル名リスト)、検証モード、エラー時の扱い(継続か停止か)、列名マッチング、アンロードへの応用などが挙げられます。
運用では「失敗した時にどこまで再実行できるか」を意識して設定しておくと安心です。
また、これらは初回の大量ロード、定時バッチ、再取り込みのリカバリーとして使われることが多いです。
-- フォーマットを明示してCSVを取り込み
CREATE OR REPLACE FILE FORMAT ff_csv TYPE=CSV SKIP_HEADER=1 FIELD_OPTIONALLY_ENCLOSED_BY='"';
COPY INTO raw.sales
FROM @my_int_stage
FILE_FORMAT=(FORMAT_NAME=ff_csv)
PATTERN='.*\\.csv' -- 必要なファイルだけを選択
ON_ERROR=CONTINUE; -- 行単位でスキップして進める上記のような形で設定することで、取り込みが行えます。
Snowpipe
Snowpipeはステージに新規ファイルが到着するたびに自動で取り込む継続ロードの仕組みです。
手動の作業を排し、データ到着から反映までの時間を短縮できます。
到着検知により小分けのファイルを自動取り込み、バッチに比べて人手の介入が少なく、運用コストを下げられるのが特徴です。
こんにちは、DX攻略部のkanoです。 「Snowflakeをもっと便利に活用したい」と思ったことはありませんか? Snowflakeを使い始めると、「データを取り込む作業」そのものが意外とボトルネックになります。 特にロ[…]

SnowpipeStreaming
SnowpipeStreamingは行単位の低レイテンシ取り込みに対応する方式です。
アプリやイベントのストリームを直接Snowflakeに反映できます。
SnowpipeStreamingは、ミリ秒〜秒オーダーでの取り込み、ファイルを介さないストリーム書き込み、パイプラインのシンプル化を実現できるという特徴があります。
クリックストリーム、IoT、リアルタイムダッシュボード、外部キューからの取り込みに活用できるという点を覚えておきましょう。
こんにちは、DX攻略部のkanoです。 DXが進まない原因は「ツール不足」ではなく、データが部門やシステムで分断され、意思決定と現場業務に届かない状態にあることが多いです。 データサイロが残ったままでは、経営ダッシュボードの数字が揃わず[…]

テーブルの種類を正しく選ぶ
用途に応じてテーブルタイプを使い分けることがコスト最適化と運用安定の近道です。
ここではSnowflakeの代表的なテーブルタイプを、特徴と使いどころ、設計の注意点、サンプルSQLとともに整理します。
永続テーブルと一時テーブル(Transient)と仮テーブル(Temporary)
永続テーブルは長期運用を前提とした標準的なテーブルで、長期保持や本番運用向けです。
一時テーブル(Transient)は短期保持や検証用途を想定したタイプで、ストレージの保護機構が簡略化されています。
コスト最適化や短期間の中間結果保持に向きで、復旧系の機能が限定的といえます。
仮テーブル(Temporary)はセッション限定で、セッションが終わると自動削除されるので、試行錯誤や一時的な前処理に最適です。
-
本番データマートや履歴保持 → 永続
-
ETLの中間結果や短期検証 → 一時(Transient)
-
Notebookや一時集計の作業台 → 仮(Temporary)
外部テーブル
外部テーブルはS3やGCSやAzure Blobなどの外部ストレージ上のファイルを移動させずに参照するテーブルです(スキーマオンリード)。
データ移動が不要でレイクの生データに直接クエリ可能で、メタデータ管理やパーティションの扱いに応じて、ディレクトリテーブルや外部テーブルのリフレッシュを併用します。
データレイクの段階で探索・検証したい時や他システムとストレージを共用していてコピーを避けたい時に活用しましょう。
ApacheIcebergテーブル
Apache Iceberg形式の表をSnowflakeで扱うためのテーブルです。
データレイクのテーブル形式と整合しやすく、スキーマ進化やスナップショット管理などの利点を活かせます。
レイクとウェアハウスの橋渡し役で、テーブル進化(列追加や型変更)を前提とした設計がしやすいのが特徴です。
また、カタログ(メタデータ管理)の置き場所や運用形態を事前に決めると後戻りが減る点も覚えておきましょう。
ApacheIcebergテーブルの使い所として、既存レイクのIceberg表をSnowflakeで高性能にクエリしたい時やバッチと準リアルタイムで一貫したテーブル運用をしたい時がおすすめです。
ハイブリッドテーブル
ハイブリッドテーブルは低レイテンシのランダム読み書きに最適化されたテーブルタイプで、アプリケーション近接のトランザクション系ワークロードをSnowflake上で扱う構成に向きます。
行単位の高速な読み書きに最適化しており、イベント処理やマイクロバッチ、アプリのバックエンド用途に適します。
従来の分析用テーブルよりも書き込み頻度の高いパターンで安定しやすい設計です。
ユーザー操作に近い更新、セッション状態の保持、イベントキューの一時保管、リアルタイム集計の前段バッファとしても有効です。
こんにちは、DX攻略部のkanoです。 企業のDX推進において、データ活用は欠かせないテーマとなっています。 大量のデータを効率よく保存し、分析や意思決定に役立てるために、多くの企業が「データウェアハウス」を導入しています。 […]

ビューとマテリアライズドビューと動的テーブル
ビューとマテリアライズドビューと動的テーブルはどれもSQLロジックを再利用するための仕組みですが、更新タイミングとコストの持ち方が異なります。
レイテンシと費用と保守性のバランスを基準に選び分けるのがポイントです。
そういった点も含めてそれぞれについて解説していきます。
ビュー
ビューは物理データを持たずに基になるテーブルや他のビューを参照する論理オブジェクトです。
ビューを使うとSQLロジックの再利用と権限分離が容易になり、列露出の最小化や命名統一にも役立ちます。
機微情報の共有にはセキュアビューを選ぶことでデータ提供先でも安全性を高められる点も重要なポイントです。
分析者向けの見やすい窓口を用意したい時や、テーブルの列構成を隠蔽したい時、外部共有のために必要最小限の列だけを見せたい時などに使いましょう。
CREATE OR REPLACE SECURE VIEW pub.v_orders AS
SELECT order_id, customer_id, amount, order_date
FROM dm.orders
WHERE is_test = FALSE;
実際に導入する際は、上記のような形で活用してみてください。
マテリアライズドビュー
マテリアライズドビューはクエリ結果をSnowflake側に保持し、基表の変更に応じて自動で維持管理されるオブジェクトです。
読み取りを非常に速くできる代わりに、更新維持のためのストレージとクレジットが発生します。
頻出で高コストな集計やフィルタの高速化。ダッシュボードの応答性向上や、ピーク時のクエリ負荷軽減に有効です。
CREATE OR REPLACE MATERIALIZED VIEW marts.mv_sales_daily AS
SELECT order_date::date AS d, SUM(amount) AS total_amount, COUNT(*) AS cnt
FROM dm.orders
WHERE is_test = FALSE
GROUP BY d;
高頻度更新の基表に対しては維持コストと効果を測定し、過剰なマテビュー増殖を避けましょう。
動的テーブル
動的テーブルは指定クエリの結果をSnowflakeが自動更新してくれる管理型の変換テーブルです。
ETLの定期実行や依存関係の管理をSnowflakeに委ねられるため、パイプラインの保守が大幅に簡素化され、レイテンシはターゲットの鮮度目標で制御することを覚えておきましょう。
生データから分析用マートまでの中間整形、継続的な増分集計、他の動的テーブルやビューを入力にした派生テーブルの構築で活躍します。
CREATE OR REPLACE DYNAMIC TABLE marts.sales_agg
TARGET_LAG = '15 minutes'
WAREHOUSE = etl_wh
AS
SELECT date_trunc('hour', order_ts) AS h, region, SUM(amount) AS total_amount
FROM dm.orders
WHERE is_test = FALSE
GROUP BY h, region;
粒度を明確にし、上流と下流で重複集計をしない構造にします。鮮度目標はビジネス要件に合わせて過不足なく設定します。
ETLツールについては、以下の記事で詳しく解説していますのでぜひ参考にしてみてください。
こんにちは、DX攻略部のkanoです。 データを扱う業務において、ETLという言葉が頻繁に登場します。 「ETLって言葉、わかってるふりをしてるけど実はわかってない…」という方はいらっしゃいませんか? 非エンジニアである私[…]

3つの違いのまとめ
ビュー、マテリアライズドビュー、動的テーブルの3つの違いをまとめると以下のようになります。
-
ビューは結果を保存しない軽量な窓口
-
マテリアライズドビューは結果を保存して読み取りを高速化
-
動的テーブルは指定クエリの結果を自動で最新化する管理型の変換テーブル
-
まずはビューで論理的な窓口を作り、共通ロジックを集約
-
応答時間が課題ならマテリアライズドビューで高速化
-
パイプラインの保守と鮮度を自動化したいなら動的テーブル
実務では、上流の生データを動的テーブルで整形し、その上にマテリアライズドビューを置いてダッシュボードを高速化、利用者には最終的にビューで提供、という多層構成が扱いやすいです。
迷ったら「参照が多いのか」「更新が多いのか」「鮮度が必要か」の3点で選びましょう。
これらの情報を踏まえた、典型パターンのミニ例は以下のようになります。
-- 1. 中間整形を動的テーブルで
CREATE OR REPLACE DYNAMIC TABLE dt_orders_clean
TARGET_LAG = '30 minutes'
WAREHOUSE = etl_wh
AS
SELECT order_id, customer_id, amount, order_ts::date AS d
FROM raw.orders
WHERE valid = TRUE;
-- 2. ダッシュボード高速化のためのマテビュー
CREATE OR REPLACE MATERIALIZED VIEW mv_orders_by_day AS
SELECT d, SUM(amount) AS total_amount, COUNT(*) AS cnt
FROM dt_orders_clean
GROUP BY d;
-- 3. 提供窓口のビュー
CREATE OR REPLACE SECURE VIEW v_orders_by_day AS
SELECT d, total_amount, cnt
FROM mv_orders_by_day;それぞれのビューの使い分けを理解して、活用してみてください。
こんにちは、DX攻略部のmukkukoです。 Snowflakeの導入成功は「導入したかどうか」ではなく、「データサイロ(部門やツールごとにデータが分断される状態)をどう解消し、運用コストやムダな処理コストをどう抑えたか」で決まります[…]

変更データを扱う用語(ストリームとタスク)
変更データで扱う「ストリーム」と「タスク」という言葉について確認していきましょう。
この2つの言葉もSnowflakeではよく出てくる言葉なので、しっかり理解しておきたい言葉です。
ストリーム(Streams)
ストリームはテーブルやビューの挿入更新削除を行レベルで追跡し、ストリームを参照する処理に変更分だけを渡します。
ストリームは読み取り専用で、ストリームを使ったDML(INSERTやMERGE)をコミットした時点で消費位置が前に進みます。
-
標準ストリーム: 挿入更新削除をすべて追跡。更新は「削除→挿入」の2行として現れます。
-
追加専用(APPEND_ONLY): 挿入のみを追跡。更新や削除は扱わないユースケースに向きます。
例えば、差分を確定テーブルへ統合する場合は以下のように設定します。
-- 元テーブルに対するストリーム
CREATE OR REPLACE STREAM st_orders ON TABLE raw.orders;
-- 変更分だけを永続テーブルへ反映
MERGE INTO dm.orders t
USING st_orders s
ON t.order_id = s.order_id
WHEN MATCHED AND METADATA$ACTION = 'DELETE' THEN
DELETE
WHEN MATCHED AND METADATA$ISUPDATE THEN
UPDATE SET amount = s.amount, order_ts = s.order_ts
WHEN NOT MATCHED AND METADATA$ACTION = 'INSERT' THEN
INSERT (order_id, amount, order_ts) VALUES (s.order_id, s.amount, s.order_ts);ストリームの運用のコツとして、ストリームにデータがあるかはSYSTEM$STREAM_HAS_DATA('st_orders')で判定するようにしましょう。
長期間消費しないとストリームが古くなる場合があるため、定期的に消費するスケジュールを設定することも大切です。
タスク(Tasks)
タスクはSQLやプロシージャの実行をスケジュールし、依存関係をDAG(有向非巡回グラフ:処理の依存関係を矢印で表したもの)として管理できます。
つまり「先に集計を作ってから、次にマートを更新する」といった順番を安全に定義しやすくなります。バッチの属人化を減らす観点でも重要な用語です。
タスクは指定したウェアハウス上で動作させる方式と、サーバーレスタスクでSnowflake管理の計算リソースを使う方式があります。
例えば、スケジュール実行の場合、以下のように設定してみてください。
-- 毎時5分に実行(タイムゾーンは例)
CREATE OR REPLACE TASK t_merge_orders
WAREHOUSE = etl_wh
SCHEDULE = 'USING CRON 5 * * * * Asia/Tokyo'
AS
MERGE INTO dm.orders ... ; -- 上のMERGE本体を置く
ALTER TASK t_merge_orders RESUME; -- 有効化重い処理や長時間処理は専用の仮想ウェアハウスに向けて他の業務と分離するようにしましょう。
こんにちは、DX攻略部のkanoです。 Snowflakeの導入や活用を外部コンサルに頼るべきか、どのように契約し何を成果物として受け取り、どんなKPIで評価すればよいか、初めてだと判断が難しいポイントが多いものです。 本記事で[…]

セキュリティとデータガバナンスの基本用語
Snowflakeは列や行単位の制御、タグや自動分類、監査や可視化の仕組みを標準で備えています。
設計段階で用語と役割を押さえると、後戻りの少ない安全なデータ基盤になるので、それに関わる用語をチェックしておきましょう。
ロールと権限
ロールと権限はSnowflakeのRBAC(ロールベースアクセス制御:役割に権限を付与する仕組み)モデルの中核です。
権限はユーザーではなくロールに付け、ユーザーはロールを割り当てて利用します。
運用では、環境(本番/開発)と職務(運用/開発/閲覧)を分け、個人への直接付与を避けるのが基本になります。
行アクセスポリシー
行アクセスポリシーは同じテーブルでも利用者の属性によって見える行を自動的に絞るための仕組みで、部門別や地域別の公開制御に向きます。
条件式はロールやユーザー、セッション変数などを参照でき、更新や削除にも同じ条件が適用されることを覚えておきましょう。
マスキングポリシー
マスキングポリシーは機微な列を動的に変換します。
閲覧者のロールに応じて値の見え方を変え、同一テーブルを安全に共有できます。
以下のような設定が代表的な形です。
-- メールアドレスを役割に応じて部分表示
CREATE OR REPLACE MASKING POLICY mp_email
AS (email STRING) RETURNS STRING ->
CASE
WHEN CURRENT_ROLE() IN ('PII_READER') THEN email
ELSE CONCAT('***@', SPLIT_PART(email,'@',2))
END;
ALTER TABLE dm.customers
MODIFY COLUMN email SET MASKING POLICY mp_email;平文を見せるロールを絞り、それ以外には伏字や部分表示を返しましょう。
こういった形であれば、監査やテストでは擬似化も有効です。
タグとデータ分類
タグはオブジェクトやカラムに付けるメタデータで、機密区分やデータオーナー、保有期限などを一元管理できます。
自動分類を使うと候補列を抽出でき、レビューしてタグ確定するフローが実務的です。
データ共有と協業(データシェアとリスティングとクリーンルーム)
Snowflakeはデータをコピーせずに共有できるのが強みです。
ここではデータシェア、リスティング、クリーンルームの違いと設計の勘所を整理します。
データシェア(DataSharing)の基本
データシェアはプロバイダーが自分のアカウント内のオブジェクトをコンシューマーに共有する仕組みです。
データシェアはコピーを作らず同一のストレージを参照するため、同期や再配布の手間がなく遅延も最小です。
コンシューマー側のクエリ実行コストは原則コンシューマーが負担し、プロバイダーは共有範囲の制御と可視化に集中できます。
データシェアの設計と権限
データシェアはテーブルやセキュアビューなどを共有対象にできます。
共有はロール経由で行い、プロバイダーは「どのDB/スキーマ/テーブルを見せるか」、コンシューマーは「どのユーザーに使わせるか」をそれぞれ自分の側で管理します。
Snowflakeアカウントを持たない相手にはリーダーアカウントを作成してデータシェアを提供する運用も可能です。
データシェアの作成例として、以下のような形が考えられます。
-- プロバイダー側: 共有の作成
CREATE OR REPLACE SHARE sales_share;
-- 共有したいオブジェクトに使用権限を付与
GRANT USAGE ON DATABASE dm TO SHARE sales_share;
GRANT USAGE ON SCHEMA dm.sales TO SHARE sales_share;
GRANT SELECT ON TABLE dm.sales.orders TO SHARE sales_share;
-- 共有先アカウントを追加(例: 組織名.アカウント名 あるいはアカウントロケータ)
ALTER SHARE sales_share ADD ACCOUNTS = ('ORG_A.CONSUMER1');
-- コンシューマー側: 共有からDBを作成
CREATE DATABASE sales_from_partner FROM SHARE PROVIDER_ORG.sales_share;この流れでコンシューマーはsales_from_partnerを自分のDBとして参照でき、閲覧や分析を自側のロールとウェアハウスで制御できます。
リスティング(SnowflakeMarketplace)
リスティングはSnowflakeMarketplaceでデータや機能を配布する手段です。
リスティングはデータシェアをパッケージ化した公開/限定公開の提供形態で、カタログ情報、利用規約、価格(有償提供の場合)を併せて管理できます。
プライベートリスティングにすれば特定の相手だけに配布可能で、公開リスティングにすれば検索経由で広く提供できます。
こんにちは、DX攻略部のkanoです。 「SnowflakeのMarketplaceって何?」 「どうやって使うの?」 Snowflake Marketplaceは、データや機能、アプリを『探す→契約する→すぐ使う』までを[…]

クリーンルーム(SnowflakeCleanRooms)
クリーンルームはプライバシーに配慮しながら複数の当事者がデータを照合・分析できるコラボレーション環境です。
クリーンルームは参加者ごとに露出範囲や集計粒度を制約し、個人を特定しない形での集計やセキュアジョインを実現します。
広告効果測定やパートナー間の重複ユーザー推定など、相互に生データを開示できない場面で有効です。
-
既存の相手に素早く安全に見せたい→データシェア
-
配布先を拡大しカタログ化や契約管理も行いたい→リスティング
-
生データを出せない前提で共同分析したい→クリーンルーム
3つの選び方の目安は上記のようなものを参考にしてみてください。
監視と運用(共有の可視化)
データ共有の運用では、どのリスティングやデータシェアがどれだけ使われているか、どのクエリがどのウェアハウスで走っているかを定点観測します。
アクセス履歴やクエリ履歴をダッシュボード化し、想定外の参照や過剰利用がないかをチェックします。
契約上の提供範囲やSLAも運用台帳に紐付けておくと棚卸しが容易です。
こんにちは、DX攻略部のkanoです。 2026年のビジネスにおいて、データは「見るもの」から「次のアクションを自動で導き出すもの」へと変わりました。 その中心にあるのがSnowflakeです。しかし、Snowflakeに蓄積された膨大[…]

運用で使う用語(ウェアハウス運用とリソースモニターとコストとキャッシュと復旧系)
現場運用では「混まないように速く安く回す」と「使い過ぎない」を両立する設計が鍵です。
ここではウェアハウス運用、リソースモニター、コストの見方、キャッシュの仕組み、復旧系の用語を実務目線で整理します。
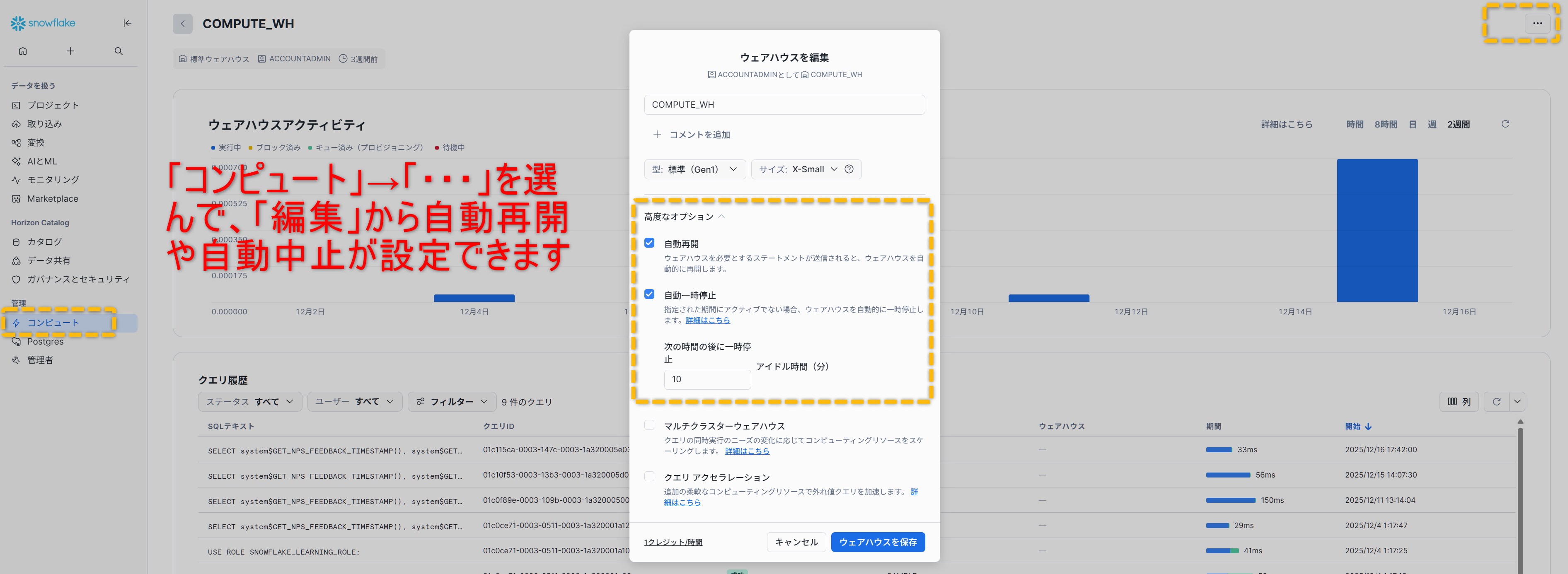
ウェアハウス運用の基本
ウェアハウスはクエリを実行する計算リソースです。
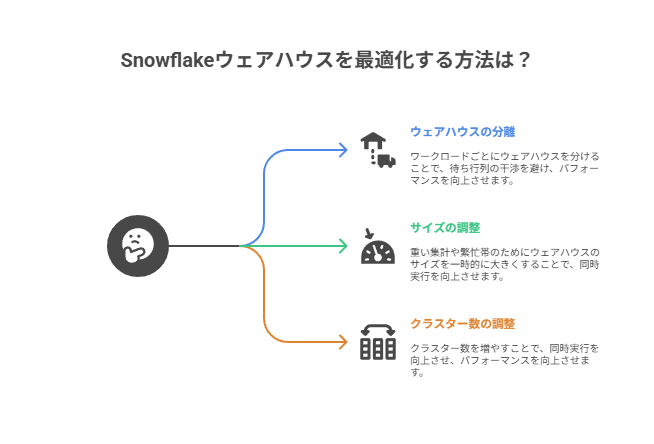
サイズとクラスター数、オートサスペンドの秒数を適切に設定し、ワークロードごとにウェアハウスを分けるのが定石です。
ダッシュボード用、取り込み用、バッチ整形用などに分離すると待ち行列の干渉を避けられます。
重い集計や繁忙帯だけ速くしたい場合は一時的にサイズを上げるか、クラスター数を増やして同時実行をさばきます。
マルチクラスターと自動サスペンド
マルチクラスターは同じウェアハウスに複数クラスターをぶら下げ、需要に応じて並列度を自動で増減します。
自動サスペンドは無負荷が続いた後にウェアハウスを停止し、コストを抑える仕組みです。
両者を組み合わせるとピークは自動で伸び、閑散時は自動停止します。
リソースモニター
リソースモニターはクレジット消費にしきい値を設け、超えたら通知や自動停止を行う仕組みです。
部門別のモニターを作りウェアハウスを割り当てると、予期せぬ使い過ぎを抑制できます。
エディションとコストの見方
Snowflakeの費用は主にクレジット(利用料金の単位)の消費として管理します。
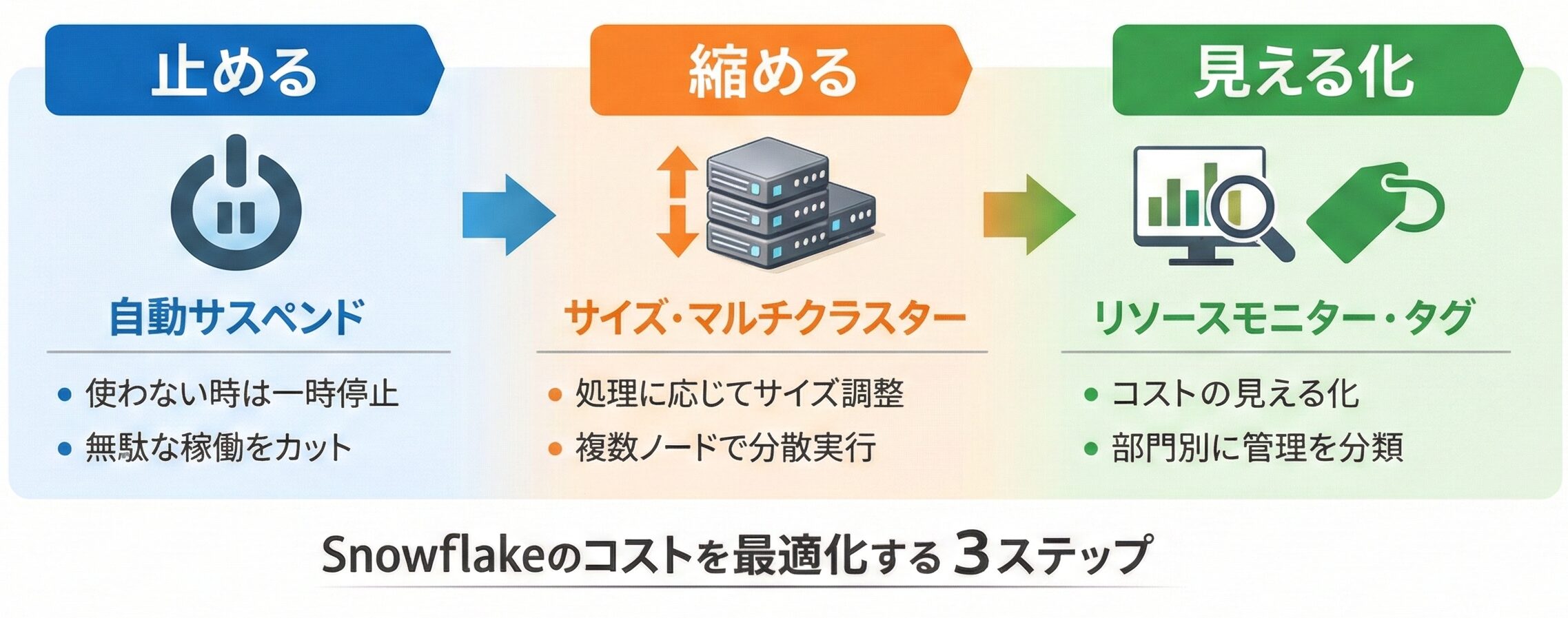
ウェアハウスは稼働時間に応じてクレジットが消費され、動的テーブルやマテリアライズドビューなど一部はサーバーレスとして別枠で消費されます。
そのため、コスト改善は「止める(自動サスペンド)」「縮める(サイズとマルチクラスター)」「見える化する(リソースモニターやタグ)」の順で進めると整理しやすくなります。
開発者向け用語(Snowparkとストアドプロシージャと外部関数とCLIとSnowSQL)
アプリや機械学習の実装で頻出する用語を確認しましょう。
Snowflake内で完結することを前提として解説していきます。
Snowpark(PythonやJavaやScala)
Snowparkはデータを動かさずSnowflake内でコードを実行するための開発フレームワークです。
DataFrameAPIでETLや特徴量生成を記述し、UDFやUDTFやUDAFで関数拡張もできます。
実行は仮想ウェアハウス上で並列化されるため、データ移動や別基盤の運用が不要になります。
こんにちは、DX攻略部のkanoです。 「SnowflakeのSnowparkで何ができるの?」 こういった疑問をお持ちではありませんか? Snowparkは、Snowflakeの中でPythonなどのコードを動かし、デー[…]

ストアドプロシージャ
ストアドプロシージャは業務処理をサーバー側に実装する手段で、タスクと組み合わせればスケジュール実行も容易です。
複数ステップの制御、例外処理、リトライ、監査ログ記録、メタデータ駆動の処理分岐などで活用できます。
外部関数
外部関数はSnowflake外のエンドポイントを呼び出して結果をSQLから利用する仕組みです。
機械学習推論や住所正規化など既存APIの再利用に向きます。
SnowflakeCLIとSnowSQL
SnowSQLは対話型のSQL実行とバッチに強い従来のCLI、SnowflakeCLIは開発者向けに範囲を広げた新CLIです。
接続や認証を共通化しつつ、アプリやデータパイプラインの操作まで一気通貫で扱えます。
使い分けの目安は、SQL中心の運用タスクや軽いバッチはSnowSQL、アプリ配布や開発者ワークフローの自動化、StreamlitやSnowpark関連の運用はSnowflakeCLIが便利です。
こんにちは、DX攻略部のkanoです。 企業のDX推進では「データを集められるか」だけでなく、「意思決定に使える状態にできるか」が成果を左右します。 ところが現場では、部門ごとにデータが分断され、集計に時間がかかり、結局は経験と勘に戻っ[…]

まとめ
Snowflakeは「インフラ準備が軽い」「データ移動が最小化できる」「権限や監査が標準で揃う」ので、小さく始めてすぐ価値を出せます。
難しい用語が多く見えても、基本の型を押さえれば導入はシンプルです。
「小さなデータを1つ取り込み、1つの動的テーブルと1つのビューを作る」ことから始めてみましょう。
Snowflakeの活用をさらに進めたい場合は、SnowflakeとStreamlitを活用することがおすすめです。
そして、DX攻略部では、Snowflake×Streamlitを活用した統合BI基盤構築支援サービスを行っていますので、Snowflake導入を検討している企業様はぜひDX攻略部にご相談ください!








