
こんにちは、DX攻略部のkanoです。
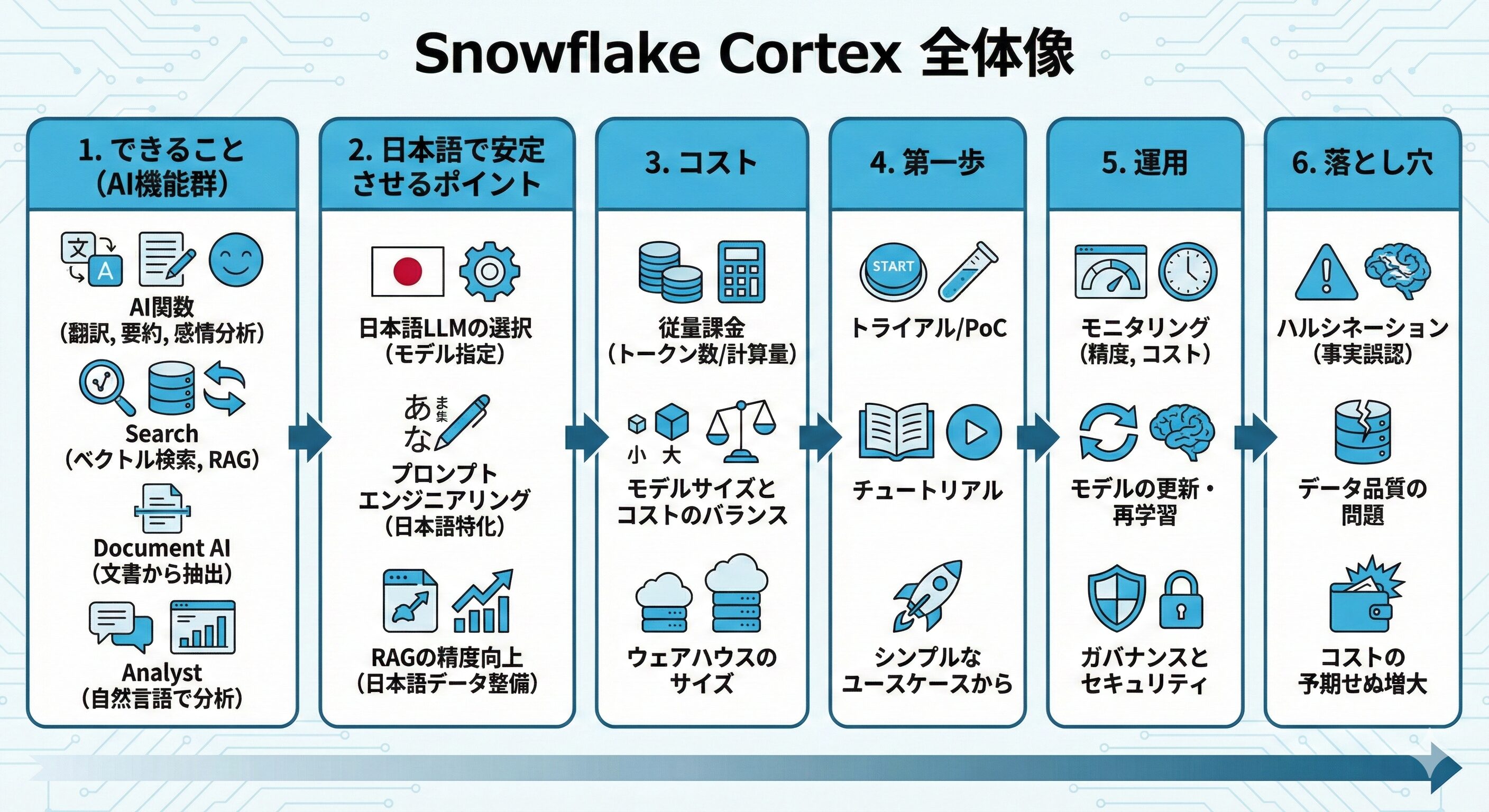
Snowflake Cortexは、社内データをSnowflakeに置いたまま、要約や分類、検索、文書の読み取りなどの生成AI活用を進められる仕組みです。
とはいえ、最初に迷うのは『どの機能から試すか』『日本語で安定させるには何が必要か』『コストと権限をどう管理するか』の3点ではないでしょうか。
この記事では、Snowflake Cortexでできることの全体像から始めて、導入の最短ルート(小さく検証→運用→拡大)までを順番に整理します。
記事の内容を確認して、Snowflakeを自社に活用してみたいと考えた方は、下記のボタンをクリックしてぜひDX攻略部にご相談ください!
Snowflake Cortexとは
ここではCortexの位置づけと構成要素を俯瞰し、用語の意味を揃えます。
概要と位置づけ
Snowflake Cortexは、Snowflakeが提供するマネージド(運用管理をサービス側が担うこと)なAI実行レイヤー(AIを呼び出して動かす共通基盤)で、社内データのガバナンスを保ったまま大規模言語モデルや検索、ドキュメント抽出を呼び出せます。
データはSnowflakeの権限管理の下で処理され、外部に散らばることなく分析やアプリに組み込めます。
主なコンポーネント
Cortexは大きく4つの柱で構成されます。
- AI関数群(AISQL):SQLから生成・翻訳・分類などを呼び出します。
- Cortex Search:ベクトルとキーワードを組み合わせたハイブリッド検索でRAG(検索拡張生成:社内文書を検索して根拠を添えて回答する方法)の基盤になります。
- Document AI:PDFや画像から表や項目を構造化抽出します。
- Cortex Analyst:自然言語の質問からSQLを自動生成し、会話的にデータ分析を進めます。
4つの柱を理解しておくことで、Snowflake Cortexをしっかりと活用できるようになります。
日本語利用の観点
日本語プロンプトや日本語データに対しても各機能をそのまま使えます。
モデルごとに得手不得手があるため、重要なユースケースは小さな検証から精度やコストを測り、モデルやパラメータを調整していくのが安全です。
Snowflakeならではのメリット
Cortexの強みは、データを外に出さずにAIを組み込める点です。
権限(RBAC:役割に権限を付与する仕組み)やマスキング(見せ方の制御)など、Snowflakeで普段使っている統制の考え方のままAI利用にも広げられます。
さらに、SQLで呼べるAI関数から小さく始め、検索(Cortex Search)や文書抽出(Document AI)へ段階的に拡張できるため、投資判断をしやすいのも特徴です。
こんにちは、DX攻略部のkanoです。 「Salesforce、MAツール、基幹システムなど導入ツールは増えたが、かえって顧客の全体像が見えにくくなった」と感じていませんか? SaaSの乱立によって生じる「データのサイロ化」は、[…]

できること(代表ユースケース)
Cortexの具体的な使いどころをイメージできるよう、現場で効果の出やすい例を取り上げます。
実際にSnowflake Cortexを使って、どのように効率化できるかの参考にしてみてください。
日常分析の自動化
レポートの要約やアラート説明、カテゴリ分類など、これまで手作業だったテキスト処理をSQL一文で自動化できます。
ダッシュボードに説明文を自動添付したり、定例レポートのドラフトを自動生成したりと、現場の省力化に直結します。
検索拡張生成(RAG)
FAQや議事録、社内ナレッジをインデックス化すると、根拠付きの回答や参考URLを返せる社内チャットを構築できます。
回答は最新の社内文書で補強されるため、ハルシネーションの抑制にも役立ちます。
帳票・契約書の自動読取り
Document AIは請求書や契約書から金額や日付、相手先などの項目を抽出し、テーブルへ安全に格納します。
抽出後はワークフローに組み込むことで、照合や承認のリードタイムを短縮できます。
ビジネスユーザーのセルフサービス分析
Cortex Analystを社内ポータルやチャットにつなげると、利用者は自然文で「先月の新規顧客数の推移を教えて」と聞くだけで結果を得られます。
SQLやデータモデルの知識が浅い部門でも意思決定が早まります。
日本語環境での利用ポイント
日本企業での導入を想定し、日本語と国内リージョンに焦点を当てた注意点をまとめます。
リージョンの選び方
日本拠点のレイテンシやデータ取り扱い要件を考慮し、原則は東京リージョンの利用を検討します。
設定はアカウント全体に影響するため、検証用アカウントで小さく試し、許容範囲を明文化してから本番に広げることが需要です。
一部機能やモデルが不足する場合は、クロスリージョン推論を有効化して補完します。
遅延や規約面の許容範囲は事前に整理しましょう。
日本語プロンプト設計
尊敬語や曖昧表現が多い日本語では、出力形式を明確に指定するほど安定します。
箇条書きやJSON形式、最大文字数などの制約を与えると、レポートへの貼り付けや後続処理が楽になります。
データの境界とガバナンス
モデルの学習に社内データが再利用されない前提で設計されますが、外部モデル連携時は各クラウドの取り扱いを確認します。
PII(個人を特定できる情報)の扱いはタグやマスキングポリシーで統制し、機密データの流出経路を塞ぎます。
コストの考え方
SnowflakeのCortex導入前に費用構造を把握し、見積もりから最適化までの流れを理解します。
課金の基本構造
AI関数は主にトークン量とモデル単価、Cortex Searchはインデックス容量と更新処理、Document AIは実行時間、Analystはリクエスト数などがコストに影響します。
どの機能でも「入力を短く」「出力を最小限に」「再利用可能な結果をキャッシュする」ことが効きます。
最初に測るべきは、トークン(AIが処理する文字量)と出力の長さ、そして同時実行数です。
AI関数は入力と出力の両方がコストに効くため、『入力を短く』『出力を最小限に』『同じ結果は再利用』の順で効きます。
見積もりと監視
見積もりは代表プロンプトを3つに絞って測り、上限(アラート基準)を先に決めてから本番に入ると、急増を防ぎやすくなります。
本番前に代表的なプロンプトでトークン量と実行時間を測り、ピーク時の同時実行数を加味して上限を見積もります。
稼働後は利用ビューで消費を可視化し、コストの高いクエリや大きな出力を特定して改善します。
最適化の具体策
プロンプトのテンプレート化で無駄な語を削り、重要語だけを残します。
Cortex Searchは差分更新で不要な再インデックスを避け、抽出・要約は短いチャンクに分けて段階処理すると安定して安くなります。
Snowflake Cortexを使うための第一歩
SnowflakeのCortexを最短で動く状態に到達するための実践的な手順を示します。
Cortexがどのように動くかを実践してみてください。
権限と前提の準備
Snowflakeの利用するロールに必要な権限を付与し、最小権限で運用を開始します。
検証・本番・管理のロールを分離し、監査可能な体制を先に整えると後戻りが減ります。
まずは検証ロールだけにCortex利用を許可し、本番ロールには通さない運用から始めると安全です。
あわせて、機微データはタグやマスキングポリシー(表示を隠すルール)で統制し、AIに渡す入力を最小化します。
『誰が、どのデータに、どの機能でアクセスしたか』が追える状態を先に作りましょう。
最初の一歩:AI関数を動かす
WorksheetsでAI関数を一つだけ試し、動作とコスト感を掴みます。
生成よりも要約や分類のような短文出力から始めると、コストの上振れを避けやすく、評価もしやすくなります。
RAGの土台を構築する
RAG(Retrieval-Augmented Generation)の土台とは、生成AIが答える前に社内データを正しく探し出せるように、知識ベースの整備と検索基盤、権限・運用をあらかじめ用意しておくことです。
チャット画面やプロンプトの工夫だけではなく、「何を、どの形で、どう検索し、どう守り、どう更新するか」という裏側の仕組みづくりが核心になります。
この土台が必要な理由は、生成AIは万能ではなく、社内の最新ルールや固有名詞は学習済みでは分からないことが多いからです。
質問のたびに社内データを取りに行き、根拠と一緒に答える、この流れを安定稼働させるためには、検索の精度、データ鮮度、アクセス制御、コスト管理まで面倒を見る基盤が欠かせません。
そのためCortex Searchで対象テーブルをインデックス化し、検索結果を根拠として回答に添えるパターンを確立します。
まずは限定的なドメイン(FAQや社内規程など)から始め、精度と鮮度の運用手順を固めます。
Document AIを小さく試す
代表的な帳票を選び、抽出項目の定義と検証を行います。
例外パターンを洗い出してフォールバック手順(手動確認や再抽出)を設けると、現場導入がスムーズです。
Analystで自然言語Q&A
データで使う用語と計算方法を「用語辞書と計算ルール」の形でまとめます。
例えば「売上=受注金額-返品金額」「新規顧客=初回購入日が当月の顧客」のように、人が読んで分かる言葉で定義します。
これをAnalystに登録しておくと、利用者が「先月の売上を教えて」のように自然文で質問したときに、その定義に沿ってSQLを自動で作り、実行してくれます。
Analystの答えが正しいかは、社内で決めた基準(業務ルール)に照らして確認しましょう。
例えば「月次レポートのKPIと一致しているか」「小計の合計が全体と合うか」などです。
万一間違いが出たときのために、誰に連絡するか(問い合わせ先)と、どの順で直すか(定義の修正、データの見直し、再テスト)の流れをあらかじめ決めておくと安心です。
運用:可観測性とガバナンス
Snowflake Cortex運用段階での見える化と統制を仕組み化し、品質と安全性を維持します。
可観測性の整備
プロンプト、入力長、応答長、応答時間、評価指標などを継続的に記録し、モデルやプロンプトの改善に生かします。
業務KPIと紐づけることで、AI導入の投資対効果を説明しやすくなります。
監査とコンプライアンス
誰がいつどのデータへアクセスしたかを記録し、定期的にレビューしましょう。
機微データはアクセスの二要素化や承認フローを併用し、逸脱があれば即時に把握できるようにします。
よくある落とし穴と対策
現場で頻出するつまずきを先回りで把握し、回避の手順を用意します。
機能やモデルの地域差
Snowflakeはリージョンによって提供状況が異なるため、システムやサービスが障害などによって停止することなく、継続して稼働できるかを事前確認します。
足りない部分はクロスリージョン推論で補いますが、遅延や規約の許容範囲を明文化しておくとトラブルを避けられます。
権限の配り過ぎ
初期設定のまま広い権限が付く構成は避け、ロールと権限を最小限で割り当てます。
検証段階で甘い設定を残すと、本番移行時の棚卸しに手間取ります。
コストの急増
Snowflake Cortexを使うとコストが急増することがあります。
その場合、長文入力や大量出力、不要な再インデックスが増加要因の場合が多いです。
トークン見積もりと上限設定、結果のキャッシュ、差分更新の活用で抑制しましょう。
日本語出力のばらつき
敬体・常体、用語表記ゆれを防ぐため、文体や専門用語の辞書をプロンプトに添えます。
出力形式を固定し、例示を増やすほど再現性が上がります。
まとめ
Snowflake Cortexについて解説しました。
Snowflake Cortexは、AI関数・検索・ドキュメント抽出・会話型分析をSnowflake内で完結させ、データ移動や複雑な基盤構築を最小化するというメリットがあります。
いままで手動で行っていた業務の負担を軽減し、別の業務にリソースを割けるのは大きなメリットがあるといえるでしょう。
導入は小さく始め、権限とガバナンスを先に整え、コストを測りながら段階的に広げるのが成功パターンです。
Snowflake内のデータを移動させず、ガバナンスを保ったまま生成AIをすばやく業務に組み込めるので、Snowflake Cortexをぜひ活用してみてください。
そして、DX攻略部では、Snowflake×Streamlitを活用した統合BI基盤構築支援サービスを行っていますので、Snowflake導入を検討している企業様はぜひDX攻略部にご相談ください!








