
こんにちは、DX攻略部のkanoです。
DXが進まない原因は「ツール不足」ではなく、データが部門やシステムで分断され、意思決定と現場業務に届かない状態にあることが多いです。
データサイロが残ったままでは、経営ダッシュボードの数字が揃わず、施策の意思決定が遅れ、同じデータ加工を部門ごとに繰り返すことでコストも膨らみます。
本記事では、データサイロを解消するための考え方と実行ステップを整理したうえで、実行段階で役立つSnowflakeの活用ポイントを解説します。
Snowflakeを導入・活用を検討している経営層、事業責任者、DX推進責任者、ならびに実務の推進担当者の方に注目していただきたい内容です。
投資判断に必要な観点(効果(売上、コスト、リスク)、期間、体制)と、最初に着手すべき領域が見える内容となっているので、ぜひ参考にしてみてください。
そして、DX攻略部では、Snowflake×Streamlitを活用した統合BI基盤構築支援サービスを行っています。
記事の内容を確認して、Snowflakeを自社に活用してみたいと考えた方は、下記のボタンをクリックしてぜひDX攻略部にご相談ください!
DXが進まない本当の理由はデータ分断にある
データが分断されていると、現場は「必要な時に必要なデータに触れられない」状態になります。
これが継続すると、意思決定が遅れ、現場の改善が止まり、DX化が進まない原因になるのです。
DX化が進まない理由について確認していきましょう。
組織のサイロ化とデータのサイロ化の連鎖
部門ごとにKPIや評価指標が異なると、システムも別々に導入されがちです。
この状態では、顧客データは営業、購買データは物流、行動データはマーケと保管場所が分かれ、横断で見られなくなります。
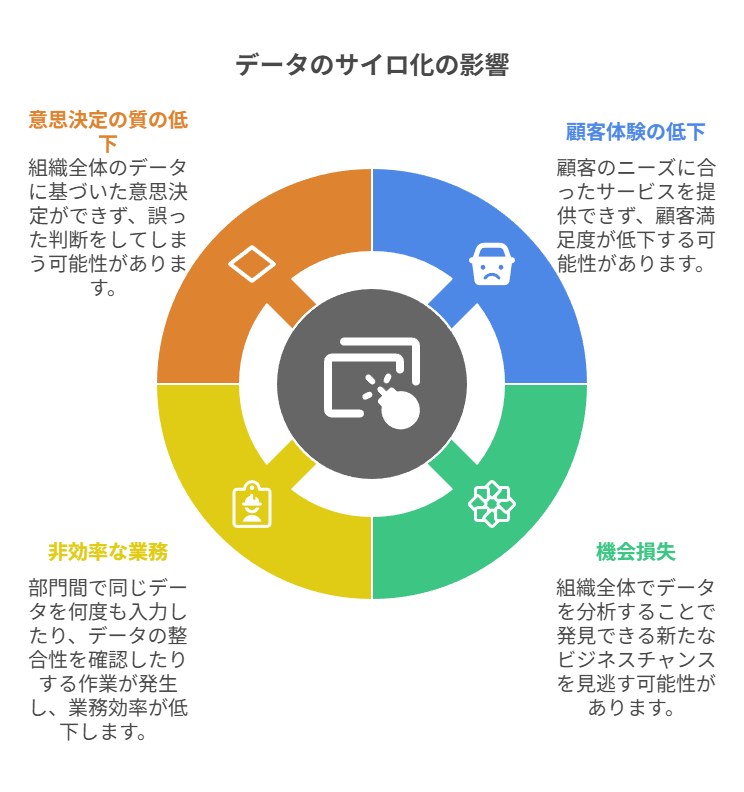
組織のサイロ(縦割り)が、データのサイロ(分断)を生み、さらに部門最適が強まる悪循環になってしまうのです。
現場にデータが届かない典型シナリオ
現場は「昨日の在庫」「顧客の最新属性」「Webの閲覧履歴」など、意思決定や対応に直結するデータを必要なタイミングで見たいものです。
ところがデータが分断されていると、申請から抽出まで数日かかる、最新データは別システムにある、形式が違って突合(複数データを突き合わせて整合性を確認する作業)できないといった状態が起きます。
この状態が続くと、施策の判断が遅れるだけでなく、現場は勘と経験に戻り、データ活用そのものの信頼が落ちてしまいます。
ツール導入先行で失敗する構造
DX化を進めるための可視化やAIのツールだけを導入しても、肝心のデータがバラバラのままでは、成果が出にくいので注意しましょう。
ツールは「水道の蛇口」、データ基盤は「配管」をイメージしてください。
配管がつながっていない状態では、どんな高性能な蛇口も水は出ません。
このことをイメージしながら、データを整える重要性を再認識しましょう。
データサイロとは
データサイロは、同じ会社内でもデータが行き来できず、重複登録や別集計が生まれる状態を指します。
データサイロに関する概要を確認していきましょう。
よくある発生源
データサイロが起きる原因は技術だけでなく、契約や権限、ルールの未整備など多岐にわたります。
データサイロの発生源の代表的な例は以下のようなものが考えられます。
- 部門最適のシステム導入:要件が部門内で完結し、全社の共通IDや標準が考慮されない
- オンプレ資産の固定化:古いDWHやファイルサーバーが残り、接続が困難
- ベンダーロックイン:専用形式や高コストのデータ移送で横断が難しい
- 契約と権限の断絶:委託先やグループ会社にデータ共有条項がなく、運用で止まる
自社が同様の状態に陥っていないか確認し、1つずつ問題を解決していかなければなりません。
データ品質のばらつきが生む二重管理と重複投資
顧客IDの桁数が違う、日付のタイムゾーンが混ざる、NULLの扱いが統一されない、こうした品質差は突合の手作業を生み、同じ処理を各部門が繰り返す「重複投資」を招きます。
事前ルールの策定やデータの整理によって、問題を解決しましょう。
個人情報や機微データで共有が止まる理由と誤解
「個人情報だから共有できない」という思い込みが障害になることがあります。
実際は、匿名化や仮名化、列マスキング(特定の項目のみ不可視化)などの技術と、目的外利用を防ぐルール設計を組み合わせれば、安全に共有できるのです。
自社が陥っている思い込みを解消することも、データサイロ問題の解消方法を考える参考にしてみてください。
データサイロがDXを止める具体的な悪影響
サイロの大きな問題は、「見えないコスト」を生み出す点です。
データサイロがDXを止める具体的な影響を紹介します。
意思決定の遅延とKPI不一致
データサイロ問題が起きやすい状態として、意思決定がしにくい環境が挙げられます。
その1つとして、部門ごとで計算式が違うと、一枚の経営ダッシュボードが作れません。
このことで、数値の整合に時間がかかり、意思決定が遅れてしまうのです。
「定義を揃える」、「参照元を単一化する」だけでスピードは大きく改善するため、見直しを進めましょう。
顧客体験の分断と機会損失
問い合わせ履歴がサポートに、購買履歴がECに、来店履歴が店舗に固定されると、チャネルをまたいだ一貫した体験が提供できません。
また、パーソナライズの精度も上がらず、離反につながります。
顧客体験の分断と機会損失も、データサイロ問題による影響といえます。
AI活用の精度低下とモデル再学習の無限ループ
近年、AIを使ったデータ分析が活発になっていますが、AIを使う際はデータを整えることが重要です。
教師データが分断されると、モデルは偏った学習をします。
予測が外れ、追加で学習しても根本原因(データの欠落や偏り)が解消されないため、再学習を繰り返すだけになります。
そのため、AIを活用する技術を高めることもデータサイロ問題の解消方法と重要といえるでしょう。
コンプライアンス違反リスクの増大
アクセス制御やログが散在すると、誰がどのデータを使ったか追跡できません。
監査対応が重くなり、法令違反のリスクが上がります。
DX化を進める上で、これらの問題を解消することで、大きなトラブルが発生するのを防げます。
データサイロ問題を解消する基本戦略
データサイロ問題の解消方法として重要なことは、「一つのプロダクト」ではなく「原則の積み重ね」の考え方を取り入れることです。
この考え方を取り入れる上で重要な4つの戦略について紹介します。
全社データ戦略とガバナンスの明文化
まずは、全社のデータ戦略とガバナンスの明文化を進めましょう。
そのためには「何のためにどのデータを使うか」、「誰が責任を持つか」を文書化します。
ガバナンスは、ルール作りだけでなく運用体制(承認フロー、監査、教育)を含みます。
シンプルな役割分担(データオーナー、データスチュワード、利用者)から始めて、問題を解消していきましょう。
共通IDとメタデータ管理(データカタログ)の徹底
共通IDは「顧客や商品を横断で結ぶ鍵」で、メタデータは「データの説明書」のことです。
そして、データカタログは、どこにどんなデータがあり、誰が使えるかを検索できる仕組みになります。
まずは最重要テーブルから、説明・更新頻度・品質指標を記載すれば、現状の問題が改善されるきっかけとなります。
収集より連携を設計する(ELT優先とデータ共有の標準化)
ELTはExtract-Load-Transformの略で「まず生データを取り込み、分析基盤内で変換する」方式です。
この方式の特徴として、取り込み口を広く保ち、変換ロジックを基盤側に集約できる点が挙げられます。
外部部門や取引先とは「どの粒度で、どのキーで、どの頻度で」共有するかを標準化し、再利用性を高めます。
このことで、各部門との連携が高まっていくのです。
セキュリティとプライバシーを設計に埋め込む(ポリシーをコード化)
データサイロ問題の解消にセキュリティとプライバシーを設計に埋め込むことで、改善につながっていきます。
アクセス権限、行レベルのフィルタ、列のマスキングを「ポリシーとしてコード化」し、環境ごとに自動適用しましょう。
監査ログとアラートも仕組みに組み込むことで、人手運用から脱却でき、トラブルを防ぐことにつながります。
まずはここから進める実行ステップ
大掛かりな改革に見えても、正しい順序で小さく始めれば成果は出ます。
データサイロ問題を解消するための、実行ステップを確認していきましょう。
重要ユースケースの特定と逆算設計
最初に「収益や顧客体験に直結するユースケース」を1〜2件選びます。
例として、「離反予測」、「在庫最適化」、「LTV向上」が挙げれます。
ユースケースから必要データと計算定義を逆算し、最小のデータ連携を設計していきましょう。
データ資産の棚卸しと短期間で達成可能な小さな成果の設定
既存のテーブル、ファイル、ダッシュボードを棚卸しし、重複や未使用を特定します。
すぐに効く改善方法として、「命名統一」、「型の揃え」、「不要列の削除」を挙げれます。
これらの改善を短期で実施して、どのような効果が表れたか確認してみてください。
短期間で達成可能な小さな成果を設定しておくことで、データサイロ問題の解消が進んでいることを確認しやすくなります。
標準化ルールと命名規則の決定
テーブル・カラムの命名、日付や通貨、タイムゾーン、NULLの扱いなどをガイドライン化します。
サンプルを提示し、レビュー時にチェックリスト化すると定着します。
パイロットの検証と拡張計画
小規模でパイロットを回し、品質・性能・権限運用を確認します。
たとえるなら、新メニューを全国発売する前に一部店舗で売ってみて、売れ行きやオペレーションの問題を確認する段階をイメージしてみましょう。
うまくいったら、同じパターンを再利用できるようテンプレート化し、適用範囲を横展開します。
Snowflakeが解決に向く理由
データサイロ問題の解消方法として、Snowflakeを活用する方法を紹介します。
Snowflakeは、データを統合して終わりではなく、「共有できる」「統制できる」「運用で回る」状態まで持っていきやすい点が強みです。
データサイロ解消は技術だけでは進まず、権限設計、監査、コスト管理などの運用要件を満たして初めて全社展開できます。
ここでは、サイロ解消の実行力につながるポイントに絞って見ていきます。
セキュアなデータ共有(データをコピーせず権限で渡せる)
Snowflakeのセキュアデータシェアは、相手先アカウントから自社データを「参照」させる仕組みです。
物理コピーが不要のため、最新版が即時に共有でき、履歴やアクセス権も一元管理できます。
グループ会社やパートナーとの定期共有に向きます。
マルチクラウド対応と自動スケーリング
主要クラウド間(例:AWS、Azure、GCP)で同等の運用が可能で、リージョンやクラウドの違いをまたいだ共有も設計しやすい点が強みです。
ワークロードのピーク時だけ自動で計算資源を増やし、終われば停止できるため、性能とコストを両立できます。
行レベルセキュリティや列マスキングによるガバナンス強化
Row Access Policy(行単位で閲覧可否を制御)やDynamic Data Masking(列の見え方を利用者属性で制御)を用いれば、同じデータでも役割に応じた安全な閲覧が可能になります。
これにより「共有したいが見せたくない部分がある」という矛盾を解消します。
マーケットプレイス活用と外部データ連携
Snowflake Marketplaceには、気象、人口統計、企業情報などの外部データが提供されています。
社内データに外部データを掛け合わせることで、需要予測や商圏分析の精度を高められます。
契約や取得の手間を減らし、素早く検証できます。
バッチとストリーミングの統合
日次のバッチ取り込みはもちろん、Snowpipeなどでほぼリアルタイムに取り込むことも可能です。
これにより「翌日まで待つ」のが前提だった現場業務を、即時性の高い体制へ切り替えられます。
ウェアハウス単位課金によるコスト最適化
コンピュート(ウェアハウス)ごとに課金が分かれ、部門や用途別にコスト配賦しやすいのが特徴です。
分析、機械学習、データ取り込みなど用途別にウェアハウスを分け、稼働時間を管理するだけでムダを減らせます。
Snowflakeに関する詳しい解説は、以下の記事も参考にしてみてください。
こんにちは、DX攻略部のkanoです。 近年、データを起点とした意思決定(データドリブン経営)がDX(デジタルトランスフォーメーション)の主戦場になりました。 しかし「社内外に散在する大量データをどうまとめ、どう活かすか」は多くの企業が[…]

Snowflake導入の設計パターン
Snowflakeを導入する際は、「構造の設計」、「可視化と統制」、「運用の自動化」を柱に進めましょう。
Snowflakeの導入の設計パターンについて解説します。
こんにちは、DX攻略部のkanoです。 Snowflake導入支援は「技術の穴埋め」ではなく、データ活用を事業の意思決定につなげるための投資を、短期間で軌道に乗せる手段です。 特に意思決定者が悩みやすいのは、導入そのものよりも「[…]

アカウントと権限の設計(ロールベースアクセス制御)
RBAC(Role-Based Access Control)で役割ごとの最小権限を定義します。
たとえば、VIEWERは閲覧のみ、ANALYSTは一時テーブル作成可、ENGINEERはスキーマ変更可、といった形です。
ロール階層を用いて、管理をシンプルにしましょう。
データ共有とデータクリーンルームの使い分け(匿名化して共同分析)
データクリーンルームは、元データを開示せずに相手と共同分析する枠組みです。
匿名化・集計済みの出力だけを共有でき、広告や小売の協業で有効です。
通常のデータ共有は信頼関係があり、詳細データを扱う場合に使います。
データカタログとタグ運用で可視化と統制を両立
テーブルや列にタグ(機微度、部門、オーナー、保持期間)を付け、検索と統制を両立します。
タグをポリシーに紐づけると、「機微=高」の列だけ自動でマスキング、といった運用が可能です。
運用監視と費用管理のベストプラクティス
クエリ履歴やウェアハウス稼働状況を定期的に可視化し、重いクエリの最適化と不要な常時稼働の削減につなげます。
あわせて、予算超過を「起きてから気づく」のではなく、上限クレジットの設定、段階的なアラート、停止ルールまでセットで用意しておくと、コストの上振れリスクを抑えられます。
意思決定者にとって重要なのは、金額の正確さだけでなく「上振れしたときに制御できるか」です。
運用のガードレールを先に設計し、稟議段階から説明できる形にしておきましょう。
Snowflake価格の最適化については、以下の記事で解説していますのでチェックしてみてください。
こんにちは、DX攻略部のkanoです。 企業がDX(デジタルトランスフォーメーション)を推進するとき、データ基盤の選定とそのコスト見通しは最初の関門になります。 Snowflakeはクラウド型データウェアハウスとして高い評価を得ています[…]

Snowflakeを使った既存環境からの移行する際のポイント
Snowflakeを使った既存環境から移行する際はいくつかのポイントに気をつけながら進めましょう。
ポイントとなるのは、「段階的」、「可視化しながら」、「価値を示しつつ」の3つです。
レガシーDWHやオンプレからの段階的移行
まずは読み取り専用で接続し、データを段階的に複製しましょう。
ゼロコピークローン(複製を高速・低コストに作る仕組み)を活用すれば、検証用環境の作成が容易です。
最初は一部のデータマートから移し、段階的に本丸へ広げます。
データ品質改善とスキーマ再設計
データ移行の機会に、キー定義の統一、参照整合性の明確化、時系列の取り扱い(有効期間カラムなど)を見直します。
いままでばらばらになっていたものをデータ移行のタイミングで整え直し、データサイロ問題を解消させる形です。
品質指標(完全性、一貫性、最新性)を定め、ダッシュボードで可視化することで、より効果を高められます。
既存BIやAI基盤との連携方法
Snowflakeは標準的な接続方式(JDBCやODBC、各種ネイティブコネクタ)に対応しており、多くのBIツールや機械学習基盤からそのまま接続できます。
認証はSSO(Single Sign-On)やサービスアカウント(システム専用の接続ユーザー)を使い、既存のアクセス管理と合わせて統制します。
BI連携は「直接クエリ」、「データマート経由」「、抽出」の3パターンが用意されているので、それを活用してみましょう。
BIから直接クエリするモデルか、中間に集約したデータマートを置くモデルかを使い分け、同時接続数やキャッシュ戦略も合わせて設計します。
こんにちは、DX攻略部のkanoです。 2026年のビジネスにおいて、データは「見るもの」から「次のアクションを自動で導き出すもの」へと変わりました。 その中心にあるのがSnowflakeです。しかし、Snowflakeに蓄積された膨大[…]

データサイロ問題を解消する際に起きやすい問題と対応方法
データサイロ問題を解消する際にトラブルが起きることがあります。
起きやすい問題と対応方法について解説します。
「データを外に出せない」への対応
もし、データサイロ問題に取り組む際にデータを外に出せない場合はどう対処すればいいのでしょうか?
そういった問題が発生した場合は、物理コピーを作らず、権限だけで参照させる共有方式を採用してみてください。
行レベル・列レベルの制御と監査ログで、アクセスを可視化し、運用ルール(目的外利用の禁止、保持期間)を契約に明記しておくことで、対応できるようになります。
「コストが読めない」への対応
データを扱う場合、どうしてもコストがかかりやすくなります。
また、どの程度コストがかかるのか読めない場合もあるでしょう。
ウェアハウス別に予算枠を設定し、自動停止とスケールポリシーで上限を管理します。
コストダッシュボードを週次でレビューし、重いクエリの最適化とスケジュールの平準化で平常時コストを抑えます。
「スキルがない」への対応
最初のユースケースに必要な最小スキルから始め、テンプレートとガイドラインを整備します。
ロールごとに教育コンテンツ(閲覧者向けのSQL基礎、運用者向けの権限設計、エンジニア向けのパイプライン設計)を用意し、内製化の土台を作ります。
こんにちは、DX攻略部のkanoです。 「Snowflakeを導入するか悩んでいる」、「実際の操作画面を触りながら使いこなせるか試したい」、「Snowflakeを導入したけど基本や応用を学びたい」 こうした状況で役立つのが、Sn[…]

まとめ
DXが進まない最大の要因は、豪華なツール不足ではなく、データが組織を横断して流れないことにあります。
まずは全社のデータ戦略を明文化し、共通IDとメタデータで「探せる・繋がる・信頼できる」土台を作り、セキュリティを設計に埋め込み、ELTと標準化で再利用性を高めましょう。
これらの原則を、小さなユースケースから着実に実装していけば、データサイロ問題を解消することに繋がります。
そして、問題解決の方法として、Snowflakeの活用もおすすめです。
Snowflakeは、コピーしない共有、細やかな権限制御、マルチクラウド対応、柔軟なコスト管理により、サイロ解消の実行力を支えます。
まずは一つのユースケースで「データが届くこと」の価値を示し、その成功パターンを横展開しましょう。
DX攻略部では、Snowflake×Streamlitを活用した統合BI基盤構築支援サービスを行っていますので、Snowflake導入を検討している企業様はぜひDX攻略部にご相談ください!








